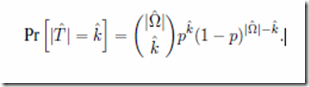There is a lot of debate in the comments to recent posts about whether the argument from ID is circular. I thought it would be worth calling this out as a separate item.
I plead that participants in this discussion (whether they comment here or on UD):
- make a real effort to stick to Lizzie’s principles (and her personal example) of respect for opposing viewpoints and politeness
- confine the discussion to this specific point (there is plenty of opportunity to discuss other points elsewhere and there is the sandbox)
What follows has been covered a thousand times. I simple repeat it in as rigorous a manner as I can to provide a basis for the ensuing discussion (if any!)
First, a couple of definitions.
A) For the purposes this discussion I will use “natural” to mean “has no element of design”. I do not mean to imply anything about materialism versus supernatural or such like. It is just an abbreviation for “not-designed”.
B) X is a “good explanation” for Y if and only if:
i) We have good reason to suppose X exists
ii) The probability of Y given X is reasonably high (say 0.1 or higher). There may of course be better explanations for Y where the probability is even higher.
Note that X may include design or be natural.
As I understand it, a common form of the ID argument is:
1) Identify some characteristic of outcomes such as CSI, FSCI or dFSCI. I will use dFSCI as an example in what follows but the point applies equally to the others.
2) Note that in all cases where an outcome has dFSCI, and a good explanation of the outcome is known, then the good explanation includes design and there is no good natural explanation.
3) Conclude there is a strong empirical relationship between dFSCI and design.
4) Note that living things include many examples of dFSCI.
5) Infer that there is a very strong case that living things are also designed.
This argument can be attacked from many angles but I want to concentrate on the circularity issue. The key point being that it is part of the definition of dFSCI (and the other measures) that there is no good natural explanation.
It follows that if a good natural explanation is identified then that outcome no longer has dFSCI. So it is true by definition that all outcomes with dFSCI fall into two categories:
- A good explanation has been identified and it is design
- No good explanation has yet been identified
Note that it was not necessary to do any empirical observation to prove this. It must always be the case from the definition of dFSCI that whenever a good explanation is identified it includes design.
I appreciate that as it stands this argument does not do justice to the ID position. If dFSCI was simply a synonym for “no good natural explanation” then the case for circularity would be obviously true. But is incorporates other features (as do its cousins CSI and FSCI). So for example dFSCI incorporates attributes such as digital, functional and not compressible – while CSI (in its most recent definition) includes the attribute compressible. So if we describe any of the measures as a set of features {F} plus the condition that if a good natural explanation is discovered then measure no longer applies – then it is possible to recast the ID argument this way:
“For all outcomes where {F} is observed then when a good explanation is identified it turns out to be designed and there is no good natural explanation. Many aspects of life have {F}. Therefore, there is good reason to suppose that design will be a good explanation and there will be no good natural explanation.”
The problem here is that while CSI, FSCI and dFSCI all agree on the “no good natural explanation” clause they differ widely on {F}. For Dembski’s CSI {F} is essentially equivalent to compressible (he refers to it as “simple” but defines “simple” mathematically in terms of easily compressible). While for FSCI {F} includes “has a function” and in some descriptions “not compressible”. dFSCI adds the additional property of being digital to FSCI.
By themselves both compressible and non-compressible phenomena clearly can have both natural and designed explanations. The structure of a crystal is highly compressible. CSI has no other relevant property and the case for circularity seems to be made at this point. But FSCI and dFSCI add the condition of being functional which perhaps makes all the difference. However, the word “functional” also introduces a risk of circularity. “Functional” usually means “has a purpose” which implies a purpose which implies a mind. In archaeology an artefact is functional if it can be seen to fulfil some past person’s purpose – even if that purpose is artistic. So if something has the attribute of being functional it follows by definition that a mind was involved. This means that by definition it is extremely likely, if not certain, that it was designed (of course, it is possible that it may have a good natural explanation and by coincidence also happen to fulfil someone’s purpose). To declare something to be functional is to declare it is engaged with a purpose and a mind – no empirical research is required to establish that a mind is involved with a functional thing in this sense.
But there remains a way of trying to steer FSCI and dFSCI away from circularity. When the term FSCI is applied to living things it appears a rather different meaning of “functional” is being used. There is no mind whose purpose is being fulfilled. It simply means the object (protein, gene or whatever) has a role in keeping the organism alive. Much as greenhouse gasses have a role in keeping the earth’s surface temperature at around 30 degrees. In this case of course “functional” does not imply the involvement of a mind. But then there are plenty of examples of functional phenomena in this sense which have good natural explanations.
The argument to circularity is more complicated than it may appear and deserves careful analysis rather than vitriol – but if studied in detail it is compelling.