
(Just found I can post here – I hope it is not a mistake. This is a slightly shortened version of a piece which I have published on my blog. I am sorry it is so long but I struggle to make it any shorter. I am grateful for any comments. I will look at UD for comments as well – but not sure where they would appear.).
I have been rereading Bernoulli’s Principle of Insufficient Reason and Conservation of Information in Computer Search by William Dembski and Robert Marks. It is an important paper for the Intelligent Design movement as Dembski and Marks make liberal use of Bernouilli’s Principle of Insufficient Reason (BPoIR) in their papers on the Law of Conservation of Information (LCI). For Dembski and Marks BPoIR provides a way of determining the probability of an outcome given no prior knowledge. This is vital to the case for the LCI.
The point of Dembski and Marks paper is to address some fundamental criticisms of BPoIR. For example J M Keynes (along with with many others) pointed out that the BPoIR does not give a unique result. A well-known example is applying BPoIR to the specific volume of a given substance. If we know nothing about the specific volume then someone could argue using BPoIR that all specific volumes are equally likely. But equally someone could argue using BPoIR all specific densities are equally likely. However, as one is the reciprocal of the other, these two assumptions are incompatible. This is an example based on continuous measurements and Dembski and Marks refer to it in the paper. However, having referred to it, they do not address it. Instead they concentrate on the examples of discrete measurements where they offer a sort of response to Keynes’ objections. What they attempt to prove is a rather limited point about discrete cases such as a pack of cards or protein of a given length. It is hard to write their claim concisely – but I will give it a try.
Imagine you have a search space such as a normal pack of cards and a target such as finding a card which is a spade. Then it is possible to argue by BpoIR that, because all cards are equal, the probability of finding the target with one draw is 0.25. Dembski and Marks attempt to prove that in cases like this that if you decide to do a “some to many” mapping from this search space into another space then you have at best a 50% chance of creating a new search space where BPoIR gives a higher probability of finding a spade. A “some to many” mapping means some different way of viewing the pack of cards so that it is not necessary that all of them are considered and some of them may be considered more often than others. For example, you might take a handful out of the pack at random and then duplicate some of that handful a few times – and then select from what you have created.
There are two problems with this.
1) It does not address Keynes’ objection to BPoIR
2) The proof itself depends on an unjustified use of BPoIR.
But before that a comment on the concept of no prior knowledge.
The Concept of No Prior Knowledge
Dembski and Marks’ case is that BPoIR gives the probability of an outcome when we have no prior knowledge. They stress that this means no prior knowledge of any kind and that it is “easy to take for granted things we have no right to take for granted”. However, there are deep problems associated with this concept. The act of defining a search space and a target implies prior knowledge. Consider finding a spade in pack of cards. To apply BPoIR at minimum you need to know that a card can be one of four suits, that 25% of the cards have a suit of spades, and that the suit does not affect the chances of that card being selected. The last point is particularly important. BPoIR provides a rationale for claiming that the probability of two or more events are the same. But the events must differ in some respects (even if it is only a difference in when or where they happen) or they would be the same event. To apply BPoIR we have to know (or assume) that these differences are not relevant to the probability of the events happening. We must somehow judge that the suit of the card, the head or tails symbols on the coin, or the choice of DNA base pair is irrelevant to the chances of that card, coin toss or base pair being selected. This is prior knowledge.
In addition the more we try to dispense with assumptions and knowledge about an event then the more difficult it becomes to decide how to apply BPoIR. Another of Keynes’ examples is a bag of 100 black and white balls in an unknown ratio of black to white. Do we assume that all ratios of black to white are equally likely or do we assume that each individual ball is equally likely to be black or white? Either assumption is equally justified by BPoIR but they are incompatible. One results in a uniform probability distribution for the number of white balls from zero to 100; the other results in a binomial distribution which greatly favours roughly equal numbers of black and while balls.
Looking at the problems with the proof in Dembski and Marks’ paper.
The Proof does not Address Keynes’ objection to BPoIR
Even if the proof were valid then it does nothing to show that the assumption of BPoIR is correct. All it would show (if correct) was that if you do not use BPoIR then you have 50% or less chance of improving your chances of finding the target. The fact remains that there are many other assumptions you could make and some of them greatly increase your chances of finding the target. There is nothing in the proof that in anyway justifies assuming BPoIR or giving it any kind of privileged position.
But the problem is even deeper. Keynes’ point was not that there are alternatives to using BPoIR – that’s obvious. His point was that there are different incompatible ways of applying BPoIR. For example, just as with the example of black and white balls above, we might use BPoIR to deduce that all ratios of base pairs in a string of DNA are equally likely. Dembski and Marks do not address this at all. They point out the trap of taking things for granted but fall foul of it themselves.
The Proof Relies on an Unjustified Use of BPoIR
The proof is found in appendix A of the paper and this is the vital line:
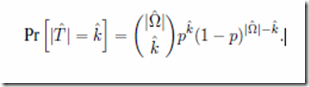
This is the probability that a new search space created from an old one will include k members which were part of the target in the original search space. The equation holds true if the new search space is created by selecting elements from old search space at random; for example, by picking a random number of cards at random from a pack. It uses BPoIR to justify the assumption that each unique way of picking cards is equally likely. This can be made clearer with an example.
Suppose the original search space comprises just the four DNA bases, one of which is the target. Call them x, y, z and t. Using BPoIR, Dembski and Marks would argue that all of them are equally likely and therefore the probability of finding t with a single search is 0.25. They then consider all the possible ways you might take a subset of that search space. This comprises:
Subsets with
no items
just one item: x,y,z and t
with two items: xy, xz, yz, tx, ty, tz
with three items: xyz, xyt, xzt, yzt
with four items: xyzt
A total of 16 subsets.
Their point is that if you assume each of these subsets is equally likely (so the probability of one of them being selected is 1/16) then 50% of them have a probability of finding t which is greater than or equal to probability in the original search space (i.e. 0.25). To be specific new search spaces where probability of finding t is greater than 0.25 are t, tx, ty, tz, xyt, xzt, yzt and xyzt. That is 8 out of 16 which is 50%.
But what is the justification for assuming each of these subsets are equally likely? Well it requires using BPoIR which the proof is meant to defend. And even if you grant the use of BPoIR Keynes’ concerns apply. There is more than one way to apply BPoIR and not all of them support Dembski and Marks’ proof. Suppose for example the subset was created by the following procedure:
- Start with one member selected at random as the subset
- Toss a dice,
- If it is two or less then stop and use current set as subset
- If it is a higher than two then add another member selected at random to the subset
- Continue tossing until dice throw is two or less or all four members in are in subset
This gives a completely different probability distribution.
The probability of:
single item subset (x,y,z, or t) = 0.33/4 = 0.083
double item subset (xy, xz, yz, tx, ty, or tz) = 0.66*0.33/6 = 0.037
triple item subset (xyz, xyt, xzt, or yzt) = 0.66*0.33*0.33/4 = 0.037
four item subset (xyzt) = 0.296
So the combined probability of the subsets where probability of selecting t is ≥ 0.25 (t, tx, ty, tz, xyt, xzt, yzt, xyzt) = 0.083+3*(0.037)+3*(0.037)+0.296 = 0.60 (to 2 dec places) which is bigger than 0.5 as calculated using Dembski and Marks assumptions. In fact using this method, the probability of getting a subset where the probability of selecting t ≥ 0.25 can be made as close to 1 as desired by increasing the probability of adding a member. All of these methods treat all four members of the set equally and are equally justified under BpoIR as Dembski and Marks assumption.
Conclusion
Dembski and Marks paper places great stress on BPoIR being the way to calculate probabilities when there is no prior knowledge. But their proof itself includes prior knowledge. It is doubtful whether it makes sense to eliminate all prior knowledge, but if you attempt to eliminate as much prior knowledge as possible, as Keynes does, then BPoIR proves to be an illusion. It does not give a unique result and some of the results are incompatible with their proof.
Excellent, Mark.
Indeed, Dembski’s arguments seem to be subject to a conservation law of their own, which we could dub the Law of Conservation of Unjustified Equiprobability. As you point out, he can’t justify an assumption of equiprobability without introducing another unjustified assumption of equiprobability. So he has yet to mitigate the fallacy in the old tornado-in-a-junkyard argument — he can only “displace” it to a higher level.
From Dembski and Marks:
If Dembski and Marks are sending dog whistles to the ID/creationist community, then all of the fundamental misconceptions of ID/creationism are contained in just these few sentences.
One simply cannot make any such assumptions about the assemblies of atoms and molecules; even in the simplest of systems. Entropy is not conserved in real atomic and molecular systems; and calling it “information” doesn’t change that fact.
Assuming maximum entropy is the same as assuming a system is isolated and has come to equilibrium so that all microstates are equally probable. This is not the kind of state in which new compounds are formed; especially the kind of compounds that would lead to the origins of self-replicating systems involved in the origins of life. These have to be formed in energy cascades in which new products get shuttled into less energetic environments where they can anneal and form stable compounds. Energy has to be released in order for atoms and molecules to bind. If a system is isolated, that energy doesn’t leave the system, and atoms and molecules cannot remain bound. The system has to be open to a larger environment.
One doesn’t have to look at complex systems to see what is wrong with using the notions in this paper as arguments for ID. Just place a few moles of hydrogen and oxygen into the same container and vary the temperature.
What possible justification can one offer for assuming equal probabilities for the various assemblies that fall out of this mixture of hydrogen and oxygen? Yet when Dembski, et. al. start talking about evolution and the origins of life, they make precisely the assumptions of this paper when they talk about atoms and molecules. In the words of David L. Abel, they assume it is all “spontaneous molecular chaos” down there.
We see the same misconceptions regarding ID/creationist confusion about genetic algorithms. They want every generation in the program to be completely scrambled. It is analogous to the belief that crystals must form from plasma, with no interactions among atoms and molecules whatsoever. It is the kind of assumption that implies that genetic algorithms are not allowed to use any observed laws in the universe.
These papers of Dembski, Marks, Abel, et. al. are the theoretical foundations of ID; but they have nothing to do with reality.
Fine-tuning arguments for ID also invoke Bernoulli’s Principle of Insufficient Reason, either explicitly or implicitly, and fail for that reason.
The fine-tuners argue that each of the relevant constants of nature must fall within a small range of values in order for life to exist, and that the odds of getting a ‘winning’ set of constants is too smal to be the result of anything but Design.
But what are the odds of getting a gravitational constant G, for example, that falls within one range of values versus another? To answer that question, you would need to know the probability distribution for all possible values of G. We only have one universe to examine, so we can’t determine the probability distribution that way. An alternative is to derive it theoretically, but we don’t yet have a solid theory of universe formation on which to base such calculations.
The fine-tuners throw up their hands and argue that in the absence of better information, they are entitled to invoke BPoIR and assume that the probability distribution is flat (all values are equiprobable). As Mark points out in the OP, this is a mistake.
Absolutely. BPoIR underlies so much of ID – not just the LCI. What I find slightly frustrating is that the rank and file of the ID community don’t even realise there is a problem. I wish I could find a way to make the point clearly, concisely and vividly.
If they didn’t have circular reasoning they wouldn’t have any at all.
I don’t like the term “some-to-many mapping”, it is unusual and unnecessary: they are talking about the reverse images of a mapping (a random variable) from Ω’ to Ω….
black smokers
In addition, the vital formula in Appendix A is just the probability for samples of (Capital Omega) things, where they are sampled from the original space with replacement. There is no reason why they could not sample without replacement, which gives you a different formula. It is arbitrary.
Here is another area that is constantly abused by ID/creationists. Yet in real investigations of the variations of “constants,” all the fundamental constants are varied as a collection. The various combinations are then checked to see what kind of universe falls out; and in many cases, one can get lots of potentially viable universes.
If one doesn’t take life as we know it in our own universe as a target, then the range of possible universes that could condense into systems of sufficient complexity becomes much greater. The “atoms” and “molecules” that make up those universes will be different from the atoms and molecules in our universe. But there are sufficient numbers of them to form an analogous “periodic” table. With analogous combinations of elements and condensed matter in these universes, who knows what might fall out?
The issues of the length of time that a universe must exist to produce life as we know it are also eliminated. The real issue has to do with the time it takes to produce condensed matter of sufficient complexity compared with the lifetime of the entire universe.
There must also be complex systems that are “soft” in the sense of soft matter in our universe. Rigid structures such as crystals do not allow enough degrees of freedom to produce viable living organisms that can undergo natural selection. Vaporized regions and plasma regions don’t appear to produce stable structures that can have memories. There have to be temperature ranges in which sufficiently complex systems can cohere and adapt and not be so rigid that they become effectively inert.
After nearly 50 years of watching ID/creationist tactics, I am not optimistic that they will ever learn science correctly.
This is a socio/political movement that has to get the science wrong in order to prop up their sectarian beliefs; and the nature of those sectarian beliefs demands that they force the rest of the society to submit to those beliefs.
At its core, ID/creationism has very little to do with science except for the fact that they use “science” to try to make their sectarian beliefs more “rational” and “compelling” than – and hence, “superior” to – other religious or non-religious beliefs. It is a more “sophisticated” form of bigotry.
Unfortunately, a lot of basically sincere people, who are members of these sects and couldn’t care less about potential conflicts between their beliefs and the findings of science, are caught up and swept along by the intense marketing campaigns and political pogroms coming out of “think” tanks like the DI, ICR, AiG, Reasons to Believe, and others.
The rest of us just have to stay alert. And we also have the National Center for Science Education to thank for keeping careful records of the political activity of ID/creationists.
One of the places where equiprobability is important to Dembski and Marks’s argument is in their Search For a Search argument. I have posted on this a couple of times (here and here) at Panda’s Thumb. They want to argue that the adaptive landscape is sampled randomly (equiprobably) out of all possible ways of associated a set of fitnesses with the set of all possible genotypes. If that were so, we could assume that a typical adaptive landscape was an impossibly jagged one on which natural selection could do little.
Such a random landscape would have no correlation between the fitnesses of neighboring points. If we take your genome and mutate it by changing one base (at one site) that would get you to a fitness that was just as bad as changing all bases in the genome at once. (… which of course would be a total disaster). So natural selection would have no traction in such a case.
The same thing is (in effect) assumed when one uses the No Free Lunch Theorem. Averaging over all possible adaptive landscapes, weighted equally, natural selection will not work effectively.
But of course real adaptive landscapes are much smoother than that, and in my posts at PT I argued that this is because they are constrained by physics, which does not allow infinitely tight interaction between everything and everything else. That is why one base changing typically does not totally destroy the organism and send us back to the primordial organic soup.
Yes. That’s why IDers are so fearful of actual studies of actual fitness landscapes.
They have already conceded that Darwinian evolution can work, given the right fitness landscape. Their only hope is to show that real fitness landscapes don’t have the necessary characteristics.
Studies like Lenski’s and Thornton’s show that this is a vain hope. And it’s only going to get worse for the IDers.
I would add that in addition to Lenski’s and Thornton’s studies, the mere fact that changing one base is much less disastrous than changing billions of bases refutes their notion of infinitely jaggy adaptive landscapes.
http://arxiv.org/pdf/1210.1444.pdf
Professor Felsenstein,
I think this is untrue. In early life, the fitness landscape was extremely jagged. Changing a single base would be distasterous.
Conversely, modern life’s fitness landscapes are smoother since organism already have all their bells and whistles in place to deal with change. So modern organisms can change numerous bases without affecting their viability. Shapiro’s NGE speaks to this capability.
Early life didn’t have those tools in place and faced much steeper mountains. Therefore, ID is the logical conclusion rather than fortuitous step-wise change.
“I would add that in addition to Lenski’s and Thornton’s studies, the mere fact that changing one base is much less disastrous than changing billions of bases refutes their notion of infinitely jaggy adaptive landscapes.”
Submitted on behalf of “Steve” (in moderation)
@ Mark Frank
Mark, can you approve it, please?
2012/10/05 at 12:39 pm | In reply to Joe Felsenstein.
Professor Felsenstein, I think this is untrue. In early life, the fitness landscape was extremely jagged. Changing a single base would be distasterous.
Conversely, modern life’s fitness landscapes are smoother since organism already have all their bells and whistles in place to deal with change. So modern organisms can change numerous bases without affecting their viability. Shapiro’s NGE speaks to this capability.
Early life didn’t have those tools in place and faced much steeper mountains. Therefore, ID is the logical conclusion rather than fortuitous step-wise change.
The landscape only gets rugged as you approach maximum “fitness.” The early steps are easy. The opposite of the claim.
Sorry – didn’t realise I could or needed to moderate comments. Done now.
You weren’t to know, Mark. Lizzie has left us to fend for ourselves for a while. Not sure if it’s some “rats in a maze” experiment!
This doesn’t agree with basic chemistry and physics. “Early life,” going all the way back to the origins, will exist in environments in which it can be stable enough to have a chance to reproduce. Rugged landscapes would correspond to high energy environments in which things are torn apart before they have a chance to settle into stable states.
Once something is in a relatively “benign” environment, and it is also capable of reproducing, then it can only explore nearby stable states. Large changes in its environment are more likely to lead to the extinction of the system.
This is basic physics and chemistry. It is what everybody experiences when they go into the lab and try to assemble such systems for research purposes. It is essential to every industrial process that produces chemicals. The products are produced in energetic environments that would destroy them if they remained there. The products must be quickly shuttled into less energetic environments.
Technical and engineering professions are familiar with the concept of annealing in which a system is gradually nudged into a desired state by various means that adjust the positions of atoms and molecules without tearing the system apart.
Evolution in a living organism is analogous to annealing in that it is the variation in its descendents, rather than the parent itself, that become the adjustments to the new environment. The variations that fit best are the ones that “settle in.”
I am the world’s worst chemist and not one to ask about the conditions of the Origin Of Life. I do suspect that competition may also have been lot less fierce back then — “enzymes” that had only slight catalyzing power might have sufficed.
But in any case the Dembski-Marks argument is not just about the OOL — it is about evolution subsequent to that as well, and evolution happening even right now. So they cannot, should not, assume that all fitness surfaces are infinitely jagged. Nevertheless their argument is assuming precisely that. As I keep saying, in effect their argument is equivalent to saying that a single base change has the same average effect as changing every base in the genome simultaneously. Which is ludicrously incorrect for any life form I know of.
Let me qualify what I just said. In their Search For a Search argument, D&M are not assuming an infinitely jagged fitness surface — they are assuming that if it isn’t that way, that this reflects some active choice by Someone who is choosing the actual fitness surface out of a bunch of mostly-infinitely-jagged ones.
In Dembski’s earlier invocation of the No Free Lunch Theorem to show that evolution could not effectively improve adaptation, he was, in effect, assuming that typical fitness surfaces were infinitely jagged, because the theorem describes only behavior averaged over the set of all possible (fitness) surfaces and almost all of those are infinitely jagged.
As I said in the Panda’s Thumb postings, the SFS argument is about the choice of fitness surfaces back at the beginning, and if they are chosen to be smoothish, then they are in effect acknowledging that evolution works to improve adaptation. I argued that the “search for a search” was made, not by a Designer but by the ordinary laws of physics.
Joe,
It’s a CYA argument. Dembski and Marks say they are skeptical of the power of unguided evolution, but they think that the SFS argument gives them a way out in case they turn out to be wrong about that. As you note, they claim that any information present in the fitness surface (and in the universe at large) had to be put there by Someone. Everything that happens after that is just the rearrangement of existing information (except when a genuine intelligence acts, in which case information is being poofed into existence and imported into the material world).
Dembski and Marks might even agree with that, but they would presumably add that the laws of physics contain information, and that the information had to come from a Lawgiver.
Of course if we accepted that the laws of physics had to come from a Lawgiver, that would still leave us able to do evolutionary biology more or less as before. It would still leave us with adaptations evolving by mutation and natural selection. So SFS, even if it were valid, is not exactly lethal to evolutionary biology.
In any case, if Dembski and Marks wanted to say that the information present in life was originally built into, not the fitness landscapes themselves, but really into the laws of physics, this is a big stretch. It would be saying that the spots on a butterfly’s wing are somehow there already, implied by the laws of physics. I wonder whether they could keep a straight face while saying that.
Yes, and that’s why I say it’s a CYA argument that Dembski and Marks don’t want to depend on unless they have to. It’s behind a door marked “Break Glass in Case of Emergency,” where “emergency” means “even we can no longer deny the creative power of Darwinian evolution”.
I think they’d say that the information was built into the laws of physics and the initial state of the universe, taken together.
Dembski is on record saying that “blind material forces can only redistribute existing information”, so if evolution shows that butterfly spots weren’t put there, directly or indirectly, by an intelligent designer, then yes, Dembski says the information had to be there already, even in the first moments of the universe’s existence.
I wonder what Dembski and Marks make of quantum randomness. Radiation is a quantum phenomenon, and radiation can cause mutations. Thus mutations can be the result of an inherently random process. Yet they can also change the course of evolution. Do Dembski and Marks think that God (or Satan, or angels, or some other non-material intelligence) is the source of every random quantum event? If not, then random quantum events are a second source of information besides non-material intelligences (a category which includes humans, according to Dembski).
Off topic, but where did Lizzie go? It doesn’t seem like her to start this place up and then just wander off.
Maybe this is an experiment to see how human males (note that it is only males) behave in unsupervised arguments (testosterone wars?) with ID/creationists. Perhaps some of her students are monitoring all this and taking notes for some research project.