
Evolution of KRAB Zinc Finger Proteins vs. the Law of Large Numbers
There are patterns in biology that violate the law of large numbers, and thus suggests Intelligent Design or at the very least statistical miracles. The pattern involves KRAB-ZnF proteins that have multiple zinc finger domains side by side that are inexact copies of each other and would require a scenario of co-evolution of their DNA binding partners with every additional zinc-finger insertion — a scenario indistinguishable from a miracle.
The role of a zinc finger can be something like a clamp or a lock. Each zinc finger in a KRAB-ZnF protein is fine-tuned to connect with a DNA much like a lock (the zinc finger) can receive a key (like DNA). Here is a depiction of a KRAB-ZnF protein with 4 zinc fingers as part of a large chromatin modifying complex. The four zinc fingers are marked “ZN” and connect to DNA:
The evolutionary explanation of side-by-side repeated patterns of zinc fingers such as in KRAB-ZnF proteins shows a severe lack of critical thinking by evolutionary biologists who pretend “phylogenetic methods” are adequate explanations of mechanical feasibility of common descent.
To illustrate the problem, consider the KRAB-ZnF protein known as ZNF136. For reference, this is the amino acid sequence of ZNF136:
https://www.uniprot.org/uniprot/P52737.fasta
This is an amino acid fragment contained within the ZNF136 protein
TGEKLYDCKECGKTFFSLKRIRRHIITH
This short sequence is called a zinc finger domain which in 3D looks like this:
https://sciencescienceeverywhere.files.wordpress.com/2015/08/figure-11.jpg
{kind=link}
Wiki gives a description of the function of zinc fingers in proteins that have them:
http://wikipedia.org/wiki/Zinc_finger
A zinc finger domain requires two “C” amino acids and two “H” amino acids placed in the right positions. It requires a few other things too…
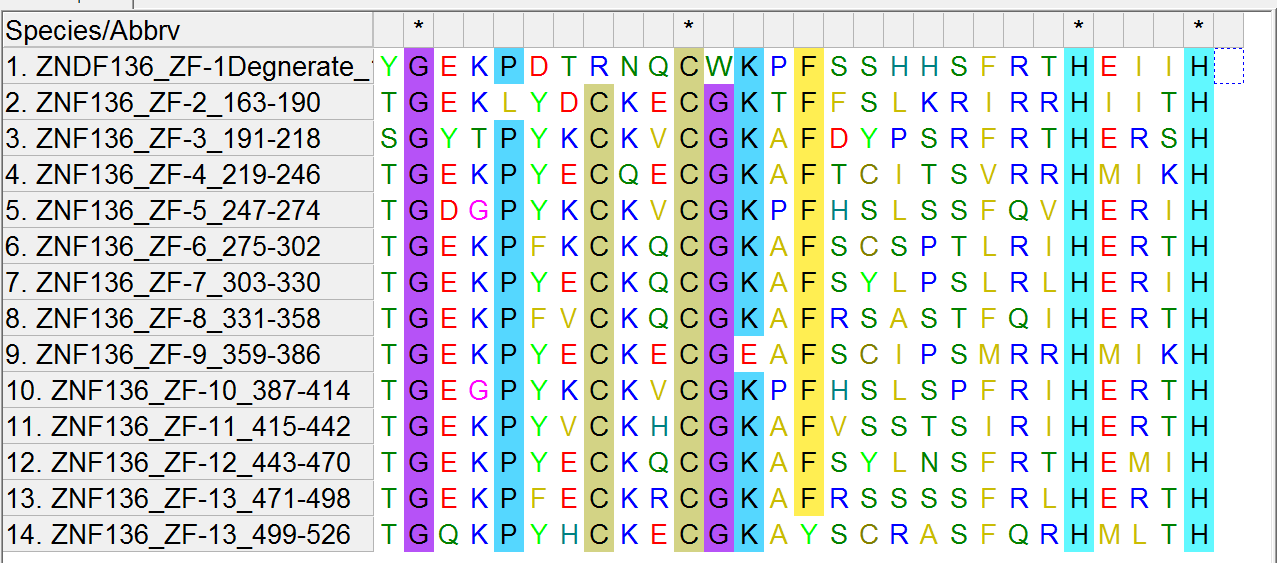
There are 13 zinc fingers in the ZNF136 protein and these are their sequences:
TGEKLYDCKECGKTFFSLKRIRRHIITH
SGYTPYKCKVCGKAFDYPSRFRTHERSH
TGEKPYECQECGKAFTCITSVRRHMIKH
TGDGPYKCKVCGKPFHSLSSFQVHERIH
TGEKPFKCKQCGKAFSCSPTLRIHERTH
TGEKPYECKQCGKAFSYLPSLRLHERIH
TGEKPFVCKQCGKAFRSASTFQIHERTH
TGEKPYECKECGEAFSCIPSMRRHMIKH
TGEGPYKCKVCGKPFHSLSPFRIHERTH
TGEKPYVCKHCGKAFVSSTSIRIHERTH
TGEKPYECKQCGKAFSYLNSFRTHEMIH
TGEKPFECKRCGKAFRSSSSFRLHERTH
TGQKPYHCKECGKAYSCRASFQRHMLTH
For completeness, there is a degenerate zinc finger in ZNF136 with the sequence “YGEKPDTRNQCWKPFSSHHSFRTHEIIH”
Why are the Zinc Fingers so different in sequence (except for the conserved amino acids)? To target a section of DNA, the zinc finger must be tuned to target it. Think of the zinc finger like a lock and DNA as a key that fits into the lock. In fact, for both the study of biology and medical applications, humans have a desire to make their own zinc fingers — like lock smiths. To bind a large segments of DNA, side-by-side zinc-fingers have to be tuned to their respective side-by-side DNA partners such as illustrated here:
By the way, there is a website that helps researchers construct the right amino acid sequence to make a zinc finger for a particular DNA target:
https://www.scripps.edu/barbas/zfdesign/zfdesignhome.php
Now, to visualize the critical/conserved amino acids, see the protein sequence here with highlights on “C” and “H” amino acids.
http://theskepticalzone.com/wp/wp-content/uploads/2019/04/znf136_zfC2H21.png
{kind=link}
Note one of the lines is not exactly like the other lines in that it is missing a “C”. This is the degenerate zinc finger mentioned above. So there is 1 degenerate zinc finger and 13 functional ones.
From this diagram it is apparent that the regular appearance of “C” and “H” is a violation of the law of large numbers, hence this pattern is not due to random point mutation alone. To “solve” this problem, Darwinist explain the pattern through segment duplication followed by some point mutation and natural selection, but this is not mechanically feasible either!
To understand why, let the reader first ponder the alignment I made of the Zinc Fingers in the ZNF136 protein using MEGA 6.0/MUSCLE software:
http://theskepticalzone.com/wp/wp-content/uploads/2019/04/znf136_zfC2H2_muscle1.png
{kind=link}
Then let the reader, consider the distance matrix generated by MEGA 6.0 which measures the number of nucleotide and percent differences between the zinc fingers.
http://www.creationevolutionuniversity.org/public_blogs/reddit/znf136_distance_matrix.xls
(All of the above results are reproducible, so I leave it to interested parties wanting to confirm the results to do so.)
For the duplication to work, at a bare minimum the right 84 nucleotide segment must be chosen, and then perfectly positioned for insertion so as not to break a pre-existing zinc finger. But supposing the duplication succeeds, why are the zinc finger’s conserved features involving “C” and “H” and other amino acids preserved and not eventually erased by point mutation given we obviously see the zinc fingers are different from each other. To preserve the “C” and “H” and other necessary amino acids in a zinc finger, the new zinc finger needs to be under selection. But in that case one is simply concocting a “just so” story for those newly minted zinc fingers without any respect for the difficulty of such a “just so” story being probable — and it is not probable!
To understand the problem of such a “just so” story, recall zinc fingers bind to DNA regions. Btw, this includes DNA regions such as ERVs! And ERVs are indicated to participate in the Stem Cell Pluripotency regulatory network:
https://www.nature.com/articles/nature13804
Further, the KRAB-ZnF protein is part of an incredibly complex machine that does chromatin modification (as shown above) by often attaching to ERV targets. But this would require that ERVs (or whatever DNA target) needs to co-evolve with the KRAB-ZnFs that attach to them!
Do these researchers even consider the fact such evolution would have to be instantaneous otherwise it would degrade function and not let the genome have the opportunity to adapt to the new accidental copy of the zinc finger because the duplication would immediately be selected against!
The above KRAB-ZnF complex is like a read/write head acting on Chromatin. Chromatin itself is an amazing mind-boggling design akin to computer ROM and RAM in one.
Again, the difficulty of evolution via random insertion/duplication mutations followed by point mutations is that such events would disrupt the binding of an already operational set of zinc fingers. For example, suppose we have an array of 10 zinc fingers side-by-side that collectively bind to a target DNA. Suppose one zinc-finger is duplicated and the number of zinc fingers is increased from 10 to 11. Oh well, the binding ability is broken or at best compromised, much like adding a single letter to a pre-existing password!
In sum, there is a violation of the law of large numbers in KRAB-ZnF proteins which is not explained by random mutation, nor random segment duplication followed by some point mutation and fixed by natural selection. Some other mechanism for the emergence of such proteins is indicated and would likely be indistinguishable from a miracle. Given the importance of such zinc finger proteins in the control of ERVs which are important in the stem cell pluripotency regulatory circuits, the origin of KRAB-ZnFs is even more miraculous.
I understand the “design argument” all right Bill. It was you who suggested that design should be the default “explanation” unless there’s a detailed explanation. So, don’t blame me for that.
colewd,
Tell me something Bill, I explained to Salvador that the classes in SCOP are not supposed to be evolutionary hierarchies. This is mentioned by one of the main authors in the SCOP web page (it’s also mentioned in the articles first presenting the database). I liked to the web page. yet, Salvador insists on his mistake, pretending that the classes are supposed to reflect common ancestry, and that the whole thing is supposed to reflect the common ancestry of all proteins.
Given that spectacular failure to read for comprehension, to even follow a link, do you really think that salvador knows what he’s talking about in this case? I hope you can answer this honestly, but I suspect that you’ll try and find some excuse.
Either way, you’ll know that this is open-faced failure. Given that, well, sorry to tell you, but his failures are that bad, and worse, in every other case. He really doesn’t understand any of it, and he doesn’t care about learning any of it.
This is an architectural diagram of a trans membrane protein. Note the segments in the protein are identical length. It echoes the problem I pointed out for zinc fingers.
The diagram is an idealization which I found in this paper:
Link to paper
Now, as far as I can tell, for this to work, the inexact “repeats” have to be in one direction for the odd numbered segments and in the other direction for the even numbered segments so that the transmembrane proteins construct the “tunnel” correctly.
I have to look for more transmembrane proteins if my hunch is right about the alternative inverted/backward copies in the segments.
Sal, long links mess with the display on small screens. As a courtesy to others, can you not use the link tags?
Stop Salvador!!!!!! You’ve got it wrong!!!!!! Pay attention please for your own sake!!!!!!
(using several exclamation marks since Salvador uses them, maybe this way he’ll see this):
Salvador,
You’re taking things out of context (how surprising). Some structural analyses can help in determining common ancestries not evident otherwise. But those are tertiary-structure comparisons accompanied by biophysical, biochemical, and statistical analyses. However, not all structural classifications are supposed to reflect common ancestry. Some can be done merely for convenience, like the higher hierarchies in the SCOP classification scheme (as they said themselves).
Had you been careful, and followed the link I provided, you could have saved this spectacular, capitals-with-multiple-quotation-marks-and-LOLs, embarrassment (taken from here):
You could have read that yourself Salvador. I suggest that next time you read carefully before adding that many exclamation marks and “LOLs” to your comments.
Yes, MEEEEEEEEEEE. I said that not all proteins come from a common ancestor, which is compatible with what I told you about SCOP. SO what’s your problem then? Why won’t you be careful then? Why insist that SCOP fails on something they didn’t intend at all?
What point would that be? That not all proteins share common ancestry? Lots of scientists already know that, and, unlike you, lots of scientists understand why. We don’t need you to tell us.
I think what’s proven, yet again, is my point, since you keep demonstrating that reading for comprehension is not your forte.
Oh!? So that failure wasn’t enough? You want to keep adding to the evidence that you cannot read for comprehension? That you prefer to embarrass yourself further than accept a little tiny correction? Let’s see that then.
Really Salvador? You say protein families and give me a list of classes (according to SCOP)? Didn’t you read above? Here it goes again: “Classes based mainly on secondary structure content and organization.”
Seems like what fails is your ability to reading for comprehension.
As I said, and as the authors of SCOP said, these classes are based on some structural feature, not implying homology. So you’re telling me what I already knew, and what SCOP stated. Of course membrane proteins belong into different families, and of course not all of them have a single common ancestor. No need for you to explain this. We already know. Calm down.
Now, please. For your own sake. Stop and think.
Sal,
I think it is appropriate to start your presentation with a slide on Duane Gish and his contributions to creationist debating styles,
Entropy,
Then you are misrepresenting it. You guys work so hard to defeat the argument you get confused what the argument is.
Entropy,
It sounds like you guys are agreeing with each other. What am I missing? You both agree demonstrating that common ancestry of proteins is a problem.
I mentioned promiscuous domains, but there must also be promiscuous motifs that act as postal codes:
https://en.wikipedia.org/wiki/Protein_targeting
A pioneer of protein targeting won the Nobel Prize. Awesome!
So the constrains on proteins are things like functioning domains properly put together along with postal address codes.
How can anyone misrepresent a non-existent argument – other than claiming there is a “Design” argument.
Well, tell us what the “Design” argument is. Describe the model and how its predictions can be tested.
(Oh the irony!)
It’s an analogy. There isn’t really a cellular postal service.
This is a transmembrane protein known as a voltage gated sodium channel. It conists of 24 transmembrane segments arranged into 4 groups of 6 segments each.
There are evolution stories concocted (not actually proven true), but they don’t address real mechanical problems of evolving something like a sodium channel.
https://en.wikipedia.org/wiki/Sodium_channel
An argument can be made from the law of large numbers that this is unlikely! I wouldn’t say astronomically unlikely, but unlikely.
I wouldn’t minimize the difficulty of forming a protein like this despite the flimsy analysis by evolutionary biologists that it can evolve by random copy and paste. There are issues related to biophysics and chemistry that need to considered.
Colewd,
Here is 2 minute video on some of the transmembrane proteins that enable our nervous system to work.
Alan Fox,
Why after 10 years or more of debating this issue you don’t understand the argument?
Alan Fox,
Here is a brief video that Patrick posted at Peaceful Science.
Of course you knew this, I just wanted you to FESS UP and admit those Hidden Markov Models by Theobald that Darwinists swear by doesn’t prove common descent of proteins unless one invokes miracles for the emergence of the founding protein of each ancestral lines
Even YOU admit the founding ancestors of the major protein families are not related by common descent, even the founding members of the major families of transmembrane protein. Thank you very much.
Good gravy how many families of proteins have no common ancestor? Orphan genes/proteins and taxnomically restricted proteins abound. POOFomorphies all the way down.
Theory! Hypothesis even? Without a hypothesis there is nothing to argue about.
Alan Fox,
How do you know there is no hypothesis if you don’t understand the theory?
What can be debated is the a priori probability of classes of event. That’s well within science. Whether that implies God or ID is a separate question.
I’ve asserted in this discussion, and for the most part at TSZ, that events claimed to be the natural course of universal common descent and/or abiogenesis would require statistical miracles.
One of the confirming evidences of this is a tenet Cell Theory:
>All cellular life arises from division of other cells.
Given this premise, this implies the first cellular life emerged as a violation of this principle — a miracle if you will.
In this thread I’ve argued for miracles in the emergence of major protein families or even some specific proteins like KRAB-ZFP.
Did God make them? That’s probably a question outside science. All that can be done, as far as science goes, is to estimate a priori probabilities of classes of events — like random tandems creating coordinated zinc-finger in transcription factors and associated networks, etc.
My claim and hypothesis:
I think that claim is well within the framework of science.
stcordova,
When we discuss probabilities it is to validate the chosen mechanisms ability to do what is claimed.
The ID claim is that a mind is a better explanation for what is being observed then blind and unguided processes. A mind appears to have a better probabilistic chance of forming a sequence or a purposefully arranged set parts then a blind and unguided process.
As more work gets done in labs like Craig Venters this hypothesis will be put to the test.
I am working on a testable hypothesis regarding the idea that the patterns of diversity and similarity that evolutionists claim are the result of common descent are better explained as optimization for scientific discovery.
One of the key elements of this is Kirk Durston’s work:
This is a chemically and physically testable hypothesis and if true, the patterns that Kirk discovered will not be well explained by random mutation and natural selection when coupled with other considerations such as patterns of strange paralogs.
State the “Design” hypothesis. (Not the best example nonsense). Then we can discuss its merits.
stcordova,
Sal, you’re still on “explain that, Evolutionists”. Let’s see an alternative we can consider.
There’s lots of things we don’t understand. So far of the things we’ve started to understand none of them have ever resolved to some god did it. Why do you suppose it’ll be different this time?
One alternative is “we don’t know” rather than “abiogenesis and evolution are fact.”
Another alternative is to simply admit “belief in natural abiogenesis is built on faith not fact” same for universal common descent.
I don’t mind saying, “I accept ID because of a grain of faith.” But I don’t pretend a statement of faith is a scientific fact like proponents of abiogenesis and universal common descent do.
If Miracles and/or God and/or ID is the reason life came to be, then perhaps as a matter of principle, these explanations can’t be reduced to explanations that are testable one demand. Like so many things we just offer our best guess at reality. Unlike many creationists and IDists, I’m at least willing to say, “it’s my best guess faith belief.”
The things we figured out can be explained by repeatable mechanisms. But with respect to life the repeatable mechanism is this:
But for cellular life to begin, it requires and exception to that law. The exception would be a miracle for reasons stated such as necessity of transmembrane proteins.
The miracle of life may not convince you of God — I respect that.
But the miracle of life is enough to convince me of God.
I’m not here to convince anyone. I’m here at TSZ to get technical review of some technical writing and presentation I’m giving.
I hope to release a video of a rehearsal of my talk soon.
Holy crap Salvador, you’ve got it wrong. repeating already debunked shit doesn’t get you off the hook. The simple admission would have. I’d leave you alone if only you were able to learn something.
I told you already that nobody’s HMM are supposed to prove that all proteins share a common ancestor. How many times more do you need to read this to understand it? You’re aking me to “fess up” to something that has never been anybody’s claim at all. Theobald knows that his HMM do not prove a universal common descent for all proteins because he knows that there’s no such thing. I told you this already, you pretended to understand, if you did, then why would you go back to this mistaken notion?
Even me? What makes you think I would not admit that not all proteins share common ancestry? What makes you think that I would not have told you myself that not all membrane proteins share common ancestry either? I’m a scientist, not some creationist bullshitter. I don’t need any push. Had you asked me I’d have told you. No fuss whatsoever.
POOFomorphies? Isn’t that precisely your position? That all proteins appeared magically? You’re shooting yourself in the foot pal.
Do you understand the concept of a false dichotomy? Because you seem to be engaging in one. That not all proteins share common ancestry doesn’t mean that they appeared magically. It just means that they don’t share common ancestry. Even you should be able to understand something this simple. Right?
Can you give a quotation for each claim from a prominent claimant?
Video-shmedio. Why not write a scientific paper?
Yes. It’s called peer review. And for some reason that’s the last thing you want.
What was the first cellular life? Can you describe it in detail?
THAT’s what I wanted you to fess up to, not HMM problem specifically.
But it’s consistent with magic starting with the functions of proteins like transmembrane proteins. I guess if one wants to invoke some sort of RNA genome rather than DNA genome for the first cell, I suppose we can grant that for the sake of argument.
But if we’re talking about cells, we do need membranes and transmembrane proteins. Don’t we?
Anyone want to disagree?
Again Salvador! What makes you think that I’d resist telling you that not all proteins share common ancestry? What exactly? Shit, fess up? Fess up what? I’ve never said otherwise for fuck’s sake.
And, yet again, there’s no HMM problem. Yet again, nobody’s HMMs are supposed to prove the universal common ancestry of proteins.
No it isn’t. That not all proteins share common ancestry is consistent with not all proteins sharing common ancestry. That’s it. Jumping from that to magic is a non sequitur.
A useless one at that. This would have nothing to do with your jump from “not all proteins share common ancestry” to “magic.”
Depends on which cells we’re talking about. I still don’t see how this justifies jumping from “not all proteins share common ancestry” to “magic.”
The best thing this would do is tell us that you can only contemplate two scenarios: no life and the modern cell. Since you cannot even imagine that there might be a path from one to the other, you think that the answer must be magic.
Well, we already knew that you think that the only option is magic. It would be helpful, however, if you didn’t project your deficient mindset onto others. That you think that way doesn’t mean that we have to think that way too.
In summary, I didn’t have anything to confess or “fess up.” I never said that all proteins shared common ancestry in the first place, and nobody’s HMMs have ever been supposed to prove the universal common ancestry of proteins.
So, please, stop the madness already. Help me have some respect for you, for your own sake. Start thinking. Read carefully. Ask modestly when you don’t get it. Respect yourself too Salvador. If you don’t think I deserve better, at a minimum you must think that you deserve better, don’t you?
The problem is not just making transmembrane proteins, but integrating them into membranes.
Now the best video I found to describe the problem doesn’t deal with prokaryotes cell membranes, but rather the eukaryotic ER. But it illustrates the problem of both integrating the protein into the membrane AND orienting it correctly (so that it’s not bass-ackward).
https://youtu.be/4qf1BSXn_tk
That’s another illustration of the problem why I think the first cell was a miracle.
[Again, the video is of a eukaryote ER, but the problem will remain for the first prokaryotic-like cell membrane]
I’d explain why what that wouldn’t be a problem for primitive cells and primitive membrane proteins. However, for the explanations to be helpful, we would have to be able to have an actual conversation, mostly meaning that you’d have to be willing to try and understand those explanations, ask as necessary for clarifications, and then offer objections, if you found any, that showed that you actually got it. I doubt we can ever reach that point.
Ok, then don’t try to explain it.
If it’s on the level of your non-sequitur of ectopic duplication necessarily providing the coordinates of a zinc finger, then I’m not that hopeful you’d give much of an explanation anyway. You’d just be wasting my time like you did with your ectopic duplication random tandem.
If, even after looking at the pretty picture, you still don’t understand how and why ectopic recombination would necessarily “provide the coordinates” of a zinc finger, time and again, then there’s not much hope that you’d understand explanations requiring a bit more understanding of molecular/biochemical interactions and their dynamics.
It’s sad to confirm that I wasted time explaining ectopic recombination to you. You didn’t even get the terms right, and you didn’t care to verify them before making this comment.
Sorry Salvador. I think you deserve better, but you disagree, and who am I to continue challenging your poor self-respect with this assumption that you might be willing and able to do better?
Alan Fox,
Intelligent design hypothesis A1.
A mind is a valid mechanism for building a living organism from non living chemicals.
A hypothesis that Craig Venter is currently testing.
Entropy,
It makes common descent an incomplete explanation for life’s diversity.
That’s a failure from the very start. A mind is not a mechanism, it’s an activity of a brain. A mind is something that can think about mechanisms.
I’d bet otherwise. I’d think that Venter is not stupid enough to expect life to get started from non-living chemicals just because he’s sitting there thinking hard.
Entropy,
Why don’t you start by defining what a mechanism is.
This is a line typical of someone trying to kill an idea for ideological reasons. It is exactly how Dawkins argues against the God hypothesis.
Entropy,
Sure he has the physical tools to arrange the chemicals but primary direction of how to arrange them comes from his mind.
1. Universal common ancestry of proteins is not required for common descent.
2. Common descent is an incomplete explanation for life’s diversity, regardless of whether proteins shared a single common ancestor or not (they don’t).
3. Common descent is but a feature in the explanation of life’s diversity.
4. Without divergence, there would be no diversity. Everything would be identical. Right?
5. Non-universal protein common ancestry is much more compatible with life’s diversity, than protein’s universal ancestry would be.
Entropy,
I agree with one through 5.
The problem is that common ancestry is an explanation with a known testable mechanism. Other evolutionary mechanisms are speculative as causes and have severe issues as to make them unable to explain what Sal is discussing.
Over the next 50 years or so we can test if a mind (with accompany of other physical attributes) can produce these organisms. If we talk about complex organisms from scratch this is going to be very difficult and probably will require a large team of minds.
Thanks Bill. I leave it here. Sorry if I came back a tad harsh.
Well, I’ll get my ideas discussed before people that are more friendly than you and who are professional biochemists and professors of chemistry and biology in decent schools and research institutions. I’ll find out whether what you say is a silly as I say it is. Thanks anyway for the conversation.
I can confidently say, I have learned squat from you except to learn how people might misinterpret what I was saying.
My TSZ post was just a warm up practice round. I picked up a few editorial pointers for my presentation, so thank you for that and thanks for keeping my thread alive.
The issue with the lack of common descent in proteins and the contrasting claim of common descent with organisms is that it suggests that common descent doesn’t seem to survive unless it invokes miracles of special creation.
I’ve posted reasons for why it’s silly to believe transmembrane protein families can just evolve naturally, it’s like expecting tornadoes passing through a junk yard and building 747 jet liners. If one can accept a few POOFs at the origin of life, one can accept more poofs in the process of common descent when warranted. And hence, like Michael Behe’s acceptance of common descent, his version of common descent is not that much different from Creationism in that it requires special events to create new systems and proteins. At what point is a special event different from an act of miraculous special creation?
Just think of all the changes in transmembrane proteins needed to transition from prokaryote to eukaryotes with membrane bound organelles, or how about the transmembrane proteins going from unicellular creatures to multi-cellular animals! WOW! And somewhere there we have the problem of promiscuous domains…
Craig Venter is at best reverse engineering. That’s a bit of a cheat, IMO. If elements can be arranged by a human into a replicating system, in mimicry of those it sees around it, that is hardly compelling evidence that there is no alternative.
[transmembrane proteins]
Skiddle-ump, skiddle-ump …
The common descent of organisms in no way entails the common descent of proteins. As a reductio ad absurdum, would it entail that all life ultimately descends from a single DNA base? That would be silly. Likewise the ‘common descent of proteins’ claim.
Haha, the nested hierarchy really bugs you doesn’t it? That’ll make John smile, if he is lurking here.
Once more: common descent does NOT depend on the mechanisms of within-lineage change. Even if certain features were lovingly crafted by the Designer in her super secret laboratory outside time and space, and sprinkled willy-nilly across her creation, all organisms can still have descended from a single ancestral population. I can’t believe you are still struggling with that, after being told so many times. Of course, if you want to claim that the Designer created features in accordance with a pattern of common descent, then your hypothesis ceases to be testable. Also, your peculiar notion that common descent of organisms entails the common descent of all proteins/ protein domains is completely misguided. Finally, if you want to express your fondness of those valuable phylogenetic patterns in your scientific work, then you should refrain from making these type of remarks: