
Evolution of KRAB Zinc Finger Proteins vs. the Law of Large Numbers
There are patterns in biology that violate the law of large numbers, and thus suggests Intelligent Design or at the very least statistical miracles. The pattern involves KRAB-ZnF proteins that have multiple zinc finger domains side by side that are inexact copies of each other and would require a scenario of co-evolution of their DNA binding partners with every additional zinc-finger insertion — a scenario indistinguishable from a miracle.
The role of a zinc finger can be something like a clamp or a lock. Each zinc finger in a KRAB-ZnF protein is fine-tuned to connect with a DNA much like a lock (the zinc finger) can receive a key (like DNA). Here is a depiction of a KRAB-ZnF protein with 4 zinc fingers as part of a large chromatin modifying complex. The four zinc fingers are marked “ZN” and connect to DNA:
The evolutionary explanation of side-by-side repeated patterns of zinc fingers such as in KRAB-ZnF proteins shows a severe lack of critical thinking by evolutionary biologists who pretend “phylogenetic methods” are adequate explanations of mechanical feasibility of common descent.
To illustrate the problem, consider the KRAB-ZnF protein known as ZNF136. For reference, this is the amino acid sequence of ZNF136:
https://www.uniprot.org/uniprot/P52737.fasta
This is an amino acid fragment contained within the ZNF136 protein
TGEKLYDCKECGKTFFSLKRIRRHIITH
This short sequence is called a zinc finger domain which in 3D looks like this:
https://sciencescienceeverywhere.files.wordpress.com/2015/08/figure-11.jpg
{kind=link}
Wiki gives a description of the function of zinc fingers in proteins that have them:
http://wikipedia.org/wiki/Zinc_finger
A zinc finger domain requires two “C” amino acids and two “H” amino acids placed in the right positions. It requires a few other things too…
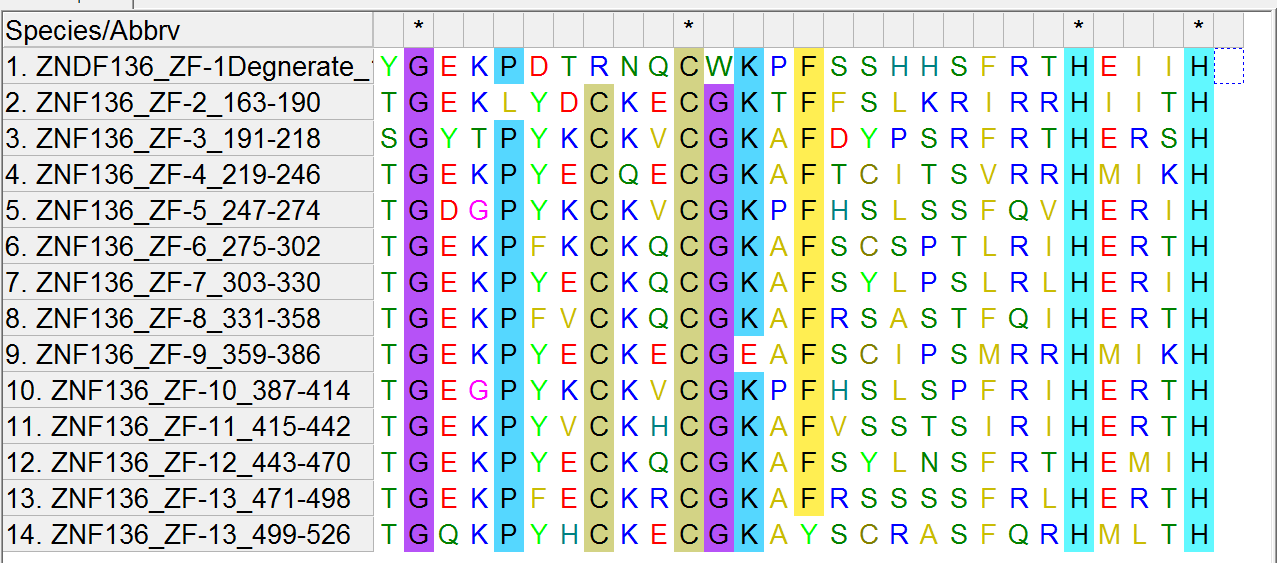
There are 13 zinc fingers in the ZNF136 protein and these are their sequences:
TGEKLYDCKECGKTFFSLKRIRRHIITH
SGYTPYKCKVCGKAFDYPSRFRTHERSH
TGEKPYECQECGKAFTCITSVRRHMIKH
TGDGPYKCKVCGKPFHSLSSFQVHERIH
TGEKPFKCKQCGKAFSCSPTLRIHERTH
TGEKPYECKQCGKAFSYLPSLRLHERIH
TGEKPFVCKQCGKAFRSASTFQIHERTH
TGEKPYECKECGEAFSCIPSMRRHMIKH
TGEGPYKCKVCGKPFHSLSPFRIHERTH
TGEKPYVCKHCGKAFVSSTSIRIHERTH
TGEKPYECKQCGKAFSYLNSFRTHEMIH
TGEKPFECKRCGKAFRSSSSFRLHERTH
TGQKPYHCKECGKAYSCRASFQRHMLTH
For completeness, there is a degenerate zinc finger in ZNF136 with the sequence “YGEKPDTRNQCWKPFSSHHSFRTHEIIH”
Why are the Zinc Fingers so different in sequence (except for the conserved amino acids)? To target a section of DNA, the zinc finger must be tuned to target it. Think of the zinc finger like a lock and DNA as a key that fits into the lock. In fact, for both the study of biology and medical applications, humans have a desire to make their own zinc fingers — like lock smiths. To bind a large segments of DNA, side-by-side zinc-fingers have to be tuned to their respective side-by-side DNA partners such as illustrated here:
By the way, there is a website that helps researchers construct the right amino acid sequence to make a zinc finger for a particular DNA target:
https://www.scripps.edu/barbas/zfdesign/zfdesignhome.php
Now, to visualize the critical/conserved amino acids, see the protein sequence here with highlights on “C” and “H” amino acids.
http://theskepticalzone.com/wp/wp-content/uploads/2019/04/znf136_zfC2H21.png
{kind=link}
Note one of the lines is not exactly like the other lines in that it is missing a “C”. This is the degenerate zinc finger mentioned above. So there is 1 degenerate zinc finger and 13 functional ones.
From this diagram it is apparent that the regular appearance of “C” and “H” is a violation of the law of large numbers, hence this pattern is not due to random point mutation alone. To “solve” this problem, Darwinist explain the pattern through segment duplication followed by some point mutation and natural selection, but this is not mechanically feasible either!
To understand why, let the reader first ponder the alignment I made of the Zinc Fingers in the ZNF136 protein using MEGA 6.0/MUSCLE software:
http://theskepticalzone.com/wp/wp-content/uploads/2019/04/znf136_zfC2H2_muscle1.png
{kind=link}
Then let the reader, consider the distance matrix generated by MEGA 6.0 which measures the number of nucleotide and percent differences between the zinc fingers.
http://www.creationevolutionuniversity.org/public_blogs/reddit/znf136_distance_matrix.xls
(All of the above results are reproducible, so I leave it to interested parties wanting to confirm the results to do so.)
For the duplication to work, at a bare minimum the right 84 nucleotide segment must be chosen, and then perfectly positioned for insertion so as not to break a pre-existing zinc finger. But supposing the duplication succeeds, why are the zinc finger’s conserved features involving “C” and “H” and other amino acids preserved and not eventually erased by point mutation given we obviously see the zinc fingers are different from each other. To preserve the “C” and “H” and other necessary amino acids in a zinc finger, the new zinc finger needs to be under selection. But in that case one is simply concocting a “just so” story for those newly minted zinc fingers without any respect for the difficulty of such a “just so” story being probable — and it is not probable!
To understand the problem of such a “just so” story, recall zinc fingers bind to DNA regions. Btw, this includes DNA regions such as ERVs! And ERVs are indicated to participate in the Stem Cell Pluripotency regulatory network:
https://www.nature.com/articles/nature13804
Further, the KRAB-ZnF protein is part of an incredibly complex machine that does chromatin modification (as shown above) by often attaching to ERV targets. But this would require that ERVs (or whatever DNA target) needs to co-evolve with the KRAB-ZnFs that attach to them!
Do these researchers even consider the fact such evolution would have to be instantaneous otherwise it would degrade function and not let the genome have the opportunity to adapt to the new accidental copy of the zinc finger because the duplication would immediately be selected against!
The above KRAB-ZnF complex is like a read/write head acting on Chromatin. Chromatin itself is an amazing mind-boggling design akin to computer ROM and RAM in one.
Again, the difficulty of evolution via random insertion/duplication mutations followed by point mutations is that such events would disrupt the binding of an already operational set of zinc fingers. For example, suppose we have an array of 10 zinc fingers side-by-side that collectively bind to a target DNA. Suppose one zinc-finger is duplicated and the number of zinc fingers is increased from 10 to 11. Oh well, the binding ability is broken or at best compromised, much like adding a single letter to a pre-existing password!
In sum, there is a violation of the law of large numbers in KRAB-ZnF proteins which is not explained by random mutation, nor random segment duplication followed by some point mutation and fixed by natural selection. Some other mechanism for the emergence of such proteins is indicated and would likely be indistinguishable from a miracle. Given the importance of such zinc finger proteins in the control of ERVs which are important in the stem cell pluripotency regulatory circuits, the origin of KRAB-ZnFs is even more miraculous.
You invoke the Law of Large Numbers, yet your piece has no numbers in it.
Please put a comment like this:
<!–more–>
somewhere early in your post.
How so?
No, it isn’t apparent at all. Explain how it is a violation.
All accounts of past events will necessarily be “just so” stories. What is the design explanation, and how is it NOT a “just so” story? And how probable is that? Show your math, calculate how “probable” it is that this exact pattern would be designed by some designer.
That makes no sense. Why would it have to be instantaneous or it would degrade function?
Why would it be selected against? Maybe it was beneficial?
Why would the putatively weaker binding of one section “break” or “compromise” the binding of the rest? Prove it, prove it that the ancestral form of the molecule would have “broken” or “compromised” the function of the moleclule.
You seem to be stuck in black and white thinking again, where either everything fits exactly in the best possible way, or it doesn’t work at all to even the slightest degree, and I’m sorry to tell you but that’s just not how the physics of molecular interactions work.
Joe Felsenstein,
@ Sal, I added a “more” tag and split your title into Title and heading.
The main problem with this OP is that the author is looking for excuses to reject the plausibility of evolution, rather than considering evolutionary scenarios. Ironically, the poor excuses are presented to try and favour a fantasy.
I doubt that Sal would understand this, even if he was measuring Kd himself.
Sal,
There is much wrong with this OP, as Rumraket notes.
Do you understand how the chelate effect works?
Particularly egregious is this howler:
We have explained this to you before, multiple times even.
You were rather slow on the uptake then, so I guess I shouldn’t be surprised that the lesson didn’t take…
DNA_Jock,
Amazing that the guy claims to be working for a PhD thesis in biophysics (or might be “finished” with it). Salvador’s spectacular incompetence should have been much more than enough reason to fail him.
Nonsense, of course. But at least you have a witty title!
Sorry about that Joe, there is a new interface in the post editor. The old interface had a button I could push to add the tag, and I didn’t know how to do it with text. Thanks a million for the info!
Thanks a million for doing this. I was having problems adding a “more” tag since the old system had a button for doing this. Apologies to the admins for my mistake. I was hoping the content manager BOT would split my text and say “continue reading” on the front page.
Sorry for all the trouble.
Allan,
So lovely to hear from you on this fine spring day that God made…
The zinc fingers would not be identified if there were not fundamentally a violation of the law of large numbers generated by random strings.
I didn’t give the numbers as I was hoping smart guys like you would help me, however two-sequence BLAST gives 23 bits for comparing zinc fingers 2 vs. zinc finger 3, and 203 bits for comparing zinc fingers 2-6 against zinc fingers 8-12, so this is non-random. One could probably use the binomial distribution to translate the violation of LLN in terms of standard deviations rather than the bit score provided by BLAST, but I see not much need of it. 203 bits is an improbability of 1 out of 2^203.
There are probably other statistical approaches to estimating the degree of violation of large numbers, but the fact the zinc fingers are recognizable at all and as repeats is a violation of the law of large numbers. Otherwise our domain search algorithms couldn’t find them with such ease!
Any way, here is a screen capture of UNIPROT identifying approximately the same set of coordinates for the repeated zinc fingers that I did in the screen capture below. UNIPROT reported the motif as length 23, but upon inspection the motif could be said to be length 28 by including 5 residues flanking toward the N-termini beside the start of each finger.
CLICK for larger image:
http://theskepticalzone.com/wp/wp-content/uploads/2019/04/uniprot_zflists.png
The original link is here:
https://www.uniprot.org/uniprot/P52737
The screen capture below is from a 2-sequence BLAST comparison I did as described in my preceeding comment. I circled in red the place where I got the bit score of 203.
CLICK here to for the screen capture:
http://theskepticalzone.com/wp/wp-content/uploads/2019/04/blast_2_report.png
The NIH website I used was:
https://blast.ncbi.nlm.nih.gov/Blast.cgi
Hey. So nice to hear from you. I was so excited that if I saw you in person and I were “Groper” Joe Biden the former USA VP I’d be kissing you and sniffing you hair. (just kidding)
Any way, the issue IS NOT that duplication happens, but rather how certain coordinates are cut and paste.
So a random copy of random length is not specifically 84 nucleotides and not specifically encompassing a pre-existing zinc finger. Oh, that’s the other problem, how did that KRAB motif get joined to a zinc finger in the first place. Not to mention, where did that KRAB motif come from to begin with? This is the problem of promiscuous domains I mentioned before.
So, no you didn’t refute my point, neither did ENTROPY. Rumraket did not refute my point either.
To refute my point you have to explain how an 84 nucleotide segment containing a zinc finger is preferentially chosen for copying. It is entirely possible a 25, 35, or whatever random length not containing a zinc finger is copied. So why do we see 13-14 inexact repeats side by side?
DNA_jock,
The other thing is this is a PROTEIN, it doesn’t describe the gene structure that has introns. I cursory look says the gene is 18,000 bases long. I don’t know how many exons for sure, but I think I saw 4 listed. I don’t know how to do such a genome search. Maybe you can help.
Otherwise if you’re just going to misrepresent what I say, just like you did, and if you’re going to throw tomatoes at straw men misrepresentations of what I say, there’s little point in us continuing to talk.
Because the duplications occur via unequal crossover during homologous recombination.
FFS, Sal!
Does anyone but Sal have any difficulty understanding this?
If so, check out the links in my comment
You misrepresented the problem that I stated.
The problem isn’t duplication per se, but why preferentially select regions containing zinc fingers? If the length and coordinate of the regions is random between iterations of duplication, one won’t get that nice side by side pattern.
Or you can choose to howl at arguments that I didn’t make bur rather that YOU concocted and attributed to me.
Here are images from the NIH CDART viewer. You can see, there zinc fingers in all sorts of proteins and in all sorts of locations on the protein. Presumably, the Zinc Fingers are located to enable the protein to function correctly.
That is proof that even if homologous recombination were in play (and somehow ignoring the interruptions of introns in the process of duplication), it doesn’t mandate putting zinc fingers so nicely side by side as I demonstrated.
See here for zinc fingers not necessarily side by side:
https://www.ncbi.nlm.nih.gov/Structure/lexington/lexington.cgi?cmd=cdd&uid=338531
Contrast with the KRAB family (including ZNF136 which I just showcased):
DNA_Jock,
It doesn’t look like Salvador is understanding it. I doubt that he went and checked. Maybe if you used puppets to explain?
I am pretty sure I did not misrepresent what you said. While seeking to refute me, you repeated the clanger…
Also, Sal, you would fare better if you could do this Genbank stuff yourself. To head off on a data-free flight of fancy is to set yourself up for a fall.
For your ZN136, the fourth and final exon starts around amino acid 60.
But the Zinc fingers don’t start until aa140. What’s that at the N terminus, aa 3 – 44, you ask?
The Krab box, which evolution bolted on…
Ooops.
Entropy,
I think that the examples with text are a lot clearer than using playdoh or puppets. That’s why I directed anyone else who does not understand to those links.
I will gladly explain this to anyone who thinks Sal has a clue.
Actually this is how Alu are thought to be copied:
Not primarily by homologous recombination. Learn some biology before bloviating.
http://www.geneticorigins.org/pv92/theory.html
I was hoping you could explain how to do this. I want to get some thing worthwhile for suffering through the insults you lob.
Can you provide links and methods to identifying the intron exon boundaries? I have the UNIPROT and Genbank protein identifiers. How do I find the corresponding genes including introns, and how can I see the exons and introns? I did this once upon a time for the Lambda Interferon 3/4, but I’ve since forgotten. Maybe you can inform me an interested readers how to do this trick.
Otherwise, I have little reason to keep wasting time correcting your misrepresentation of the problem stated.
Explain why this 84 stretch of nucleotides (28 amino acids) or any other one like it (such as the other zinc fingers) is PREFERENTIALLY selected for copying, or are you saying copies aren’t preferentially chosen for homologous recombination. Which every answer you give will be problematic.
TGEKLYDCKECGKTFFSLKRIRRHIITH
Ok, say you recombine the nucleotides and create a frame shift? BOOM!
You want to stick to that silly argument.
Let’s see if I have this right.
The argument seems to be:
(1) Something improbable happened; therefore
(2) evolution is refuted.
I think I’ve seen that argument before. It comes in many different versions.
I can’t explain why it rained last night. Therefore god.
stcordova,
I was not claiming that Alu’s arise via homologous recombination. Read the linked comments.
My point is a simple one. Tandem repeats can increase or decrease in repeat number via homologous recombination. These operations will precisely maintain the repeat size (say 84 nucleotides) with no need for any “precision” of any kind at all.
Glad to explain this to anyone who doubts this.
Here’s an analogy that occurred to me at lunch:
Songs can increase or decrease in number of verses over time.
Generally, what happens is someone repeats (or drops) a verse, with some variation. The cross-over occurs during the chorus.The cross-over could occur anywhere at all in the chorus, with identical effect.
Absolutely amazingly and in contravention of the Law of Large Numbers the insertion is always exactly 16 bars long.
What are the odds?
Guano’ed this comment, Entropy.
For the sake of the children.
I knew that already Salvador. I wasn’t talking about how Alu elements multiply (transpose), I was talking about DNA_Jock’s made up illustration here (I doubt you have the ability to follow the link, even though all it requires is clicking on it), which used an hypothetical aluGENEalu “word” as a basic repeating unit. I was very clear about it, and I was talking to DNA_Jock, who, being the author of the example, surely knows what I was talking about.
Learn to read and follow links before bloviating.
Not only that, if you cannot explain why it rains “preferentially” during raining season, then you haven’t explained anything, therefore god.
And then, if your explanation for rainy season doesn’t explain why it rained out of raining season, then you explained nothing, therefore god.
And then, if your explanation for rain-out-of-raining-season doesn’t also explain dry season, then you explained nothing at all, therefore god.
[move goal-posts ad nauseam]
I dont think you guys should be so hard on Sal. He may seem obtuse but at least hes grappling with the details of evolution. I just watched the slick new video by the DI on the “Dissenters Of Darwin” There are a some good scientists on the list, like James Tour, and as always, they present their “skepticism” as the reasonable skepticism that all scientists are supposed to have. But if any of them were forced to address the detailed evidence for evolution, the only way they could maintain their “skepticism” would be to make statements as ridiculous as Sal frequently makes.
Ok, well hes attempting to at least. My point is that most of the people who accept ID only talk in vague generalities.
These are mechanisms of gene duplication:
https://en.wikipedia.org/wiki/Gene_duplication#Mechanisms_of_duplication
Is anyone here asserting these mechanisms were involved in the duplication of the 84 nucleotide (corresponding to 28 amino acids) segments in question?
Which one is picked to explain the copying of ZincFinger containing domain?
How are frame shift problems avoided?
Also, this is the amino acid sequence for zinc finger 3 (zf3). I could have chosen any zinc finger, but this is for illustration.
SGYTPYKCKVCGKAFDYPSRFRTHERSH
and zf4
TGEKPYECQECGKAFTCITSVRRHMIKH
this the sequence of zf3 and zf4 combined
SGYTPYKCKVCGKAFDYPSRFRTHERSHTGEKPYECQECGK
AFTCITSVRRHMIKH
this is the sequence of the last letter of zf3 and the first letter of Zf4
HT
Ok, so I do a duplication and insertion, making the generous implicit assumption this wasn’t causing a frame shift that blows away the codons. I added a little spacing for clarity:
SGYTPYKCKVCGKAFDYPSRFRTHERSHT
HT
GEKPYECQECGKAFTCITSVRRHMIKH
Which easily breaks the 83 nucleotid/28 amino acid repeating pattern. More random duplications will damage the pattern even more.
Or how about residues 9-12 of zf3
CKVC
that get duplicated and inserted
SGYTPYKCKVCCKVCGKAFDYPSRFRTHERSH
Bye-bye zinc finger!!!!
Thanks!
Btw, here’s a nice repeating pattern of Glycines in Collagen:
Click to ENLARGE image below:
http://www.creationevolutionuniversity.org/public_blogs/reddit/collagen_v2.png
The collagen repeat isn’t explainable by tandem repeats. Look carefully at the non-repeating patterns of the residues between the repeating Glycines and you’ll see the problem.
This is a violation of the law of large numbers and not explicable by tandem repeat mini/micro-satelites mechanisms. At best one might invoke selection building out the repeat, but there has to be more than Glycine in every 3rd position but also properly positioned Proline-Glycine pairs to effect proper post translation modification by this enzyme:
https://en.wikipedia.org/wiki/Procollagen-proline_dioxygenase
The Proline-Glycine motif has to be modified so that the twist in collagen occurs on average at 3.3 residues. So the G has to be repeated every 3 residues and the twist ever 3.3 residues! The PG motif has to be positioned to agree and/or effect the proper twisting in a HomoTrimer of collagen.
What would you expect to see if the results were compatible with the law of large numbers and why?
Non-orderly patterns where we don’t have the same letter appearing at regular intervals. A random number generator should not be generating the same number at regular intervals.
One could tie a random number generator to generate character strings, and if it’s a good randomizer it won’t make the same character show up at regular intervals.
The law of large numbers predicts that over large strings, if the string is a randomly generated string with only modest bias for some characters, we won’t see the same letter appear regularly as it does in Collagen (where “G” is repeated every 3rd letter for a very long stretch).
There are proteins that are non-orderly in sequence, in fact, I think that would be the case for most proteins!! I found at least two exceptions to the rule (KRAB-ZNFs and Collagens).
The two proteins I highlighted are special cases. The most NON-random pattern I found is in collagen.
The ZNF136 protein has a non-random pattern in it, but it’s not quite as apparent as collagen:
http://theskepticalzone.com/wp/wp-content/uploads/2019/04/znf136_zfC2H21.png
The way the C’s and H’s line up is non-random. Each row that has a highlighted pair of C’s and H’s is a zinc-finger domain. The pairs repeat 13 times every 28 letters. Since there are 20 possible amino acids, a ROUGH estimate of the improbability of C’s repeating 13 times this way is:
1 out of 20^13
It’s not astronomically remote, but it is not highly probable either. The other important thing is this architecture of C’s and H’s are found in other proteins. 3% of proteins in Nematode worms have zinc fingers — I would guess a comparable figure exists in humans. It’s a very common theme in proteins.
Also, collagens account for about 25-35% of human body protein by weight!
The present argument is whether random duplication mutations can create this elegant pattern.
FWIW, I’m presenting these two proteins before a group of associates who are university professors and post docs to get their thoughts because there may be some interest in the ID quarters regarding the ideas I’ve laid out.
I posted this at TSZ to get some editorial feedback and critical review.
Not all of them.
Both DNA_Jock and me already told you: homologous recombination (called “ectopic” in the link you posted).
To understand that all you need to understand is what the word “homologous” implies. Since recombination happens in homologous segments, the frame is conserved by mere DNA complementarity.
And here you have already made a huge mistake. You’re talking about copies, yet you want to start with already divergent sequences. The proper start is a duplicate that has sequences identical to each other. For example, a duplicate of the first one:
SGYTPYKCKVCGKAFDYPSRFRTHERSHSGYTPYKCKVCGKAFDYPSRFRTHERSH
Once that one is in place, any “ectopic” (homologous) recombination will result in further expansion and reduction of the repeat.
So, for example, recombining these in any “wrong-yet-homologous-position” would result in multiples always of the right size:
SGYTPYKCKVCGKAFDYPSRFRTHERSHSGYTPYKCKVCGKAFDYPSRFRTHERSH
SGYTPYKCKVCGKAFDYPSRFRTHERSHSGYTPYKCKVCGKAFDYPSRFRTHERSH
Above, imagine recombinations anywhere between the italiced parts of the sequences will result in recombinations looking as if “perfectly” performed at the boundaries, even if the happened at, say, the KAFDYPSRFRTHERSH parts:
SGYTPYKCKVCGKAFDYPSRFRTHERSHSGYTPYKCKVCGKAFDYPSRFRTHERSH
SGYTPYKCKVCGKAFDYPSRFRTHERSHSGYTPYKCKVCGKAFDYPSRFRTHERSH
We’d get:
SGYTPYKCKVCGKAFDYPSRFRTHERSHSGYTPYKCKVCGKAFDYPSRFRTHERSHSGYTPYKCKVCGKAFDYPSRFRTHERSH
Which is a “perfectly bounded” triplet of the original:
SGYTPYKCKVCGKAFDYPSRFRTHERSH
SGYTPYKCKVCGKAFDYPSRFRTHERSH
SGYTPYKCKVCGKAFDYPSRFRTHERSH
After this, it’s easy to see how the segment could continue increasing in length, time and again looking as if the boundaries were the points where the recombination occurred, even if it happened anywhere else.
Divergence between sequences would make them less and less similar until recombinations would become less likely between older duplicates, but still possible between younger ones.
I don’t know how to make the font smaller and align the sequences to illustrate this with much more clarity, but, following the example carefully should allow anybody who’s authentically interested in understanding to follow.
ETA: The collagen one would continue expanding and contracting by both slippage and homologous recombinatrion.
stcordova,
I think you are misusing the term. It represents the fact that broader and broader samples approach the expected value of a distribution – the mean of the entire population. Samples are more representative of the full set the bigger they are, I don’t quite see how that ties in with your thesis here.
OK, let’s see if this shit works:
You didn’t present a point to be refuted. You made claims, but have not shown how those claims follow from anything.
Coming from the the guy spraying all his posts liberally with political and religious trolling. As if we’d forgotten your religious and political views and needed to be reminded because stating them is really important to the point of your thread?
Hey, maybe they ARE the point of this thread? This is all, at bottom, about your religious and political views.
Sal, we already knew that.
Ah, thank you so much for the correction. That was worth the price of me posting. But it only makes my point stronger. I learn something, and you don’t. Haha!
SGYTPYKCKVCGKSGYTPYKCKVCGKSGYTPYKCKVCGKSGYTPYKCKVCGKSGYTPYKCKVCGK
That’s not a functioning zinc finger. By copying as you suggested, a functioning zinc finger is destroyed.
Thank you very much for both your correction and proving my point. You’re a pal.
The collagen is an easier example. But let’s take a non biological example. Say we have a fair die. Say we had 6000 rolls of the dice. If every sixth roll we roll a 6, that would be a violation of the law of large numbers in that we would expect that on average we would role a 6 only 1/6th of the time. Using the binomial distribution we can compute how far from expectation of the mean this is.
In the case of the die the odds of 100% 6’s every sixth role is:
1 out 6^1000,
whereas the mean is anticipated to be 16.6666…%
The odds of being within 2 standard deviations of this 16% is what — 95%? The standard deviation is approximated as follows:
Now instead of die rolled 6000 times (6000 trials) we only have 13 segments (13 trials), and instead of every 6th roll were looking at every 28th amino acid for ZNF136.
I’m not arguing for astronomically remote odds, but this is still pretty remote. I haven’t worked out the issue of the entire zinc finger architecture because we need to have CxxC somewhere and then HxxxH not too far away, plus there have to be some sort of connection sequences plus the correct alpha helix and an anti parallel beta sheet and this entails some specific CLASSES of residues. This would make the odds even more remote, but the math a little less elegant.
I’m going to put this on the table in a few weeks before a discussion group that does have some specialization.
My TSZ post was a preliminary cleanup of my outline.
Thanks for your comment.
My point was said in the FIRST PARAGRAPH:
Actually my mistake was saying Entropy provided a correction. He did not!
https://en.wikipedia.org/wiki/Gene_duplication#Ectopic_recombination
The zinc finger sequences were on the same gene even though the zinc fingers were not identical. Ectopic recombination deals with
The sequences don’t have to be already repetitive on the gene! Although it helps.
That said note:
https://en.wikipedia.org/wiki/Tandem_repeat
Soooo, this raises the question how those inexact tandem repeats came to be. I essentially covered why the inexactness is non-random because of the DNA binding partners of the individual zinc fingers with the fact that the zinc finger structure features of CxxC and HxxxH have to be preserved plus some other things.
That’s your claim, you haven’t shown that the claim is true. You understand the difference between making a claim, and explaining how it’s truth follows, right?
No it doesn’t make your “point” stronger, and no, you learned nothing. You just doubled down in your display of ignorance. This is why I so quickly lost respect for you. Instead of learning something you make shit up.
Don’t be silly, it doesn’t make sense that the function would be destroyed. Each zinc finger remains intact, and there’s plenty more than one protein with zinc fingers where these events can occur.
Didn’t you say you’re a “biophysics guy”? If you were you’d understand that the more repeats the more stable the interaction between the protein and the DNA sequence. That’s why several zinc fingers tend to be in a single protein, because they work in numbers better than alone.
I didn’t prove your point, but you made mine, since, just as I said, you have no idea what you’re talking about, yet you arrogantly make ignorant claim after ignorant claim to try and compensate. Sorry, it doesn’t work that way. When caught in your ignorance, you should stop making yet more ignorant claims and start making an effort to learn and understand instead. Have some self-respect Salvador.
If your imaginary friend was real he would be ashamed of your way to defend your “faith.” That, however, doesn’t seem to bother you, meaning that maybe you’re not so sure that he exists after all.
Since you cannot read for comprehension, then look at the fucking picture Salvador!! Look at the “B” segment. It’s a different illustration of the very same process I drew, only at a different level (producing repeated genes, rather than repeated domains). It can happen between any repetitive sequences, be it within a gene or without. The principle is the very same. Stop the desperate quote-mining. It doesn’t work. You need to understand the processes involved instead!!
I know you didn’t like that my drawing showed you wrong so obviously, that it showed how easily “exact length” copies arise. But that’s life. Now just grow up. Act your age. You’re too old to continue displaying such desperate childish denial.
stcordova,
You err in regarding amino acid residues as equivalent to dice rolls. You don’t know the distribution, and haven’t accounted for all mechanisms and constraints in your (implied) calculations. This is the ‘Hoyle-o-matic’ mode of protein evolution.
Try calculating the probability of getting a given protein segment of length l to be duplicated to a given locus in the correct frame – or modelling it, computationally, with a digital population working at it. I’m willing to bet it’s not astronomical.