
Allan Miller’s post Randomness and evolution deals with neutral drift in the Moran model applied to a bag of M&Ms. Much of the discussion has focused on the question of counting generations in a situation where they overlap. I think it’s a good idea to divert that part of the discussion into its own thread.
Here are the rules. Start with a population of N M&Ms. A randomly chosen M&M dies. Another randomly chosen M&M gives birth to a child M&M. Repeat.
Because the focus of this thread is generation count and not fixation, we will pay no attention to the colors of M&Ms.
How do we count generations of M&Ms?
- My recipe. Count the number of deaths and divide by N. It can be motivated as follows. A single step (one death and one birth) replaces 1 out of N M&Ms. We need at least N steps to replace the original M&Ms.
- Joe Felsenstein’s recipe. The original M&Ms are generation 0. Children of these M&Ms are generation 1. Children of generation n are generation n+1. The generation count at any given point is obtained by averaging the generation numbers of the population.
- Replacement recipe. A generation passes when an agreed-upon fraction of the current population (e.g., 90 percent) is replaced.
Numerical experimentation with the Moran model shows that recipes 1 and 2 give similar generation counts in a large population, say, N=1000. I suspect that the third recipe will give a generation count that differs by a numerical factor. In that case one can select the “right” fraction that will yield the same count as the first two recipes.
Have at it.
ETA. Let us define generations as Joe did (definition 2 above): the original organisms are generation 0, their children are generation 1, and so on. Let us call N deaths and N births one cycle.
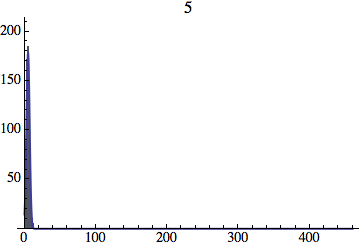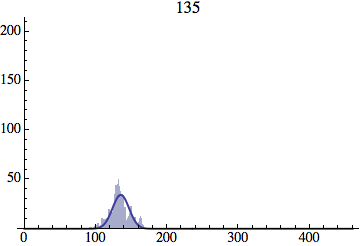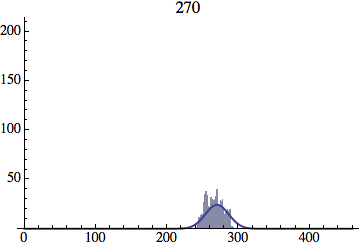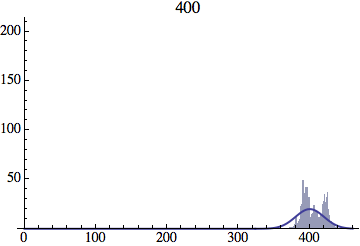
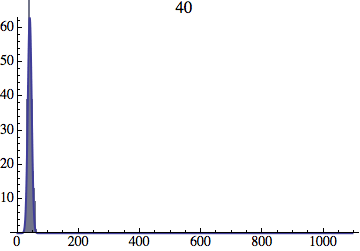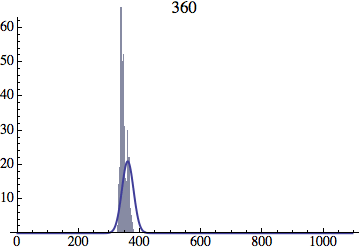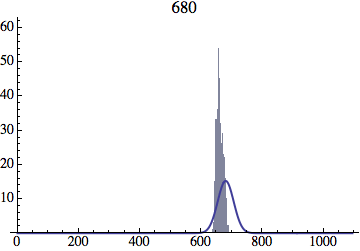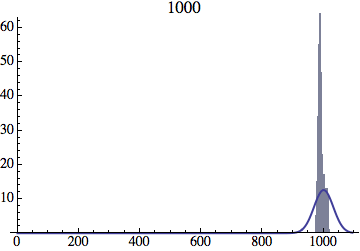
I wrote a simple Mathematica script that plots the distribution of generations after a given number of cycles. Here are a few representative histograms for N=1000 organisms after T=100 cycles.
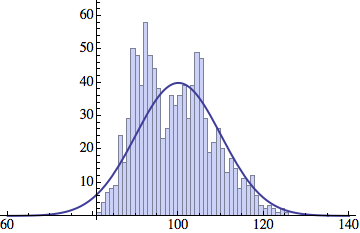
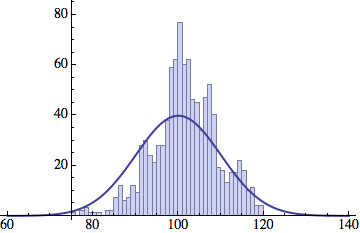
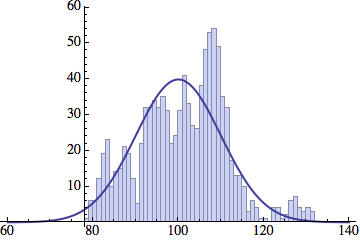
The curve is the Gaussian distribution with the mean equal to the number of cycles T and the standard deviation equal to the square root of T.
Averaging over 100 different runs (each with a population of 1000) gives a distribution that is nicely reproduced by the Gaussian curve:
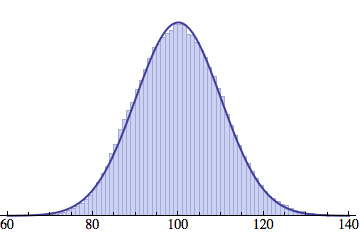
And here is an animated GIF file showing the evolution of the generation distribution with time (in cycles of N deaths and births).
Joe Felsenstein pointed out if we follow the distribution of generations to times t longer than N, we will find that its width stops growing and remains around the square root of N/2. (Here is also my take on it.) The animated GIF below shows longer-term behavior of the distribution, to t=1000 in a population of N=1000. You can see clearly that toward the end of this interval the distribution is narrower and taller than the Gaussian it is supposed to follow.
But your question is really about process rather than results.
I’ve only seen one person at UD program a sim GA and observe the results. He eventually dropped out, I assume because his program confirmed what we say about GAs And contradicted what the regulars were claiming.
It is my opinion that the only way you can understand this is to program it yourself. You have to see how each piece works.
Everyone can make up their own mind about what looks like reality to them.
Of course they only could if someone would actually show what they did, instead of just going on and on about why they won’t show it.
I already ran the program myself. The results are ludicrous, happy now?
Write your own damn code, phoodoo, and investigate the output till your heart’s content. And if you are lazy or incompetent, politely ask others to share their results. No one here owes you anything.
I told you, I already did. The results are preposterous. there you go. Your claims were incorrect.
Specifically in what way?
So why not show *your* results, as you are asking others to do?
I vote Poe.
The results were ludicrous.
That isn’t specific. Try again.
Remain calm everyone. Rule one: assume all others are posting in good faith.
I’m putting A. Fox in guano for starting the rot with the Schaffly remark.
ETA and responses to it.
I moved some more comments to guano. Everyone has the option of posting again within the rules of this site.
Let me guess. This test was supposed to be with M&Ms but half the time when you pulled them from the bag you thought they said W&W. No wonder you’re confused and reject the test results. 🙂
phoodoo
If you think you have been unfairly treated, take it up in the moderation thread. I’ll move your comment there and respond there.
Applies to anyone else who has a complaint about moderation.
Been there, done that. Watch the web simulator in the other thread. It becomes a jumble pretty quickly. They don’t last too long overall before being replaced by the new children.
We also implemented a simplified birth, maturity, aging process. They had to age a while before they could reproduce, then they died after a certain age.
It didn’t change anything substantially.
I vote Joe.
Would be happy to review your algorithm. Can you post it?
For the math of a more realistic model of overlapping generations, see my 1971 paper in Genetics “Inbreeding and Variance Effective Numbers in Populations with Overlapping Generations”. Available here from the journal with no paywall. There is also a lovely paper by Bill Hill in 1972 that simplifies the formula and gives an argument that can be extended more generally.
It turns out that the effective population number of a human population in an industrial society is about 1/3 the census number. Using that effective population size, we can predict how fast genetic drift will go.
(Unless someone thinks the math is wrong).
phoodoo,
Sigh. You’d need Excel to run the sim – it is a vba macro. Of course I could just dump the data, but I would prefer to do some formatting, which requires work. But you running the sim as often as you think necessary would be the ideal solution. The output from the vba is formatted (in Excel). Here’s what happens when i just dump it. I know how to get round that, but – I am currently being paid to do something entirely different
population size 300 population size 500 population size 700
Events Ancestor label fixed Gens (approximate method) Mean Gens (counted) Min Gens (counted) Max Gens (counted) Events Ancestor label fixed Gens (approximate method) Mean Gens (counted) Min Gens (counted) Max Gens (counted) Events Ancestor label fixed Gens (approximate method) Mean Gens (counted) Min Gens (counted) Max Gens (counted)
85233 270 284.11 287.660007 271 298 185320 168 370.64 340.4840162 311 368 340642 12 486.6314286 475.0099949 455 505
104865 125 349.55 351.6333418 321 371 346417 306 692.834 689.3860327 666 706 326996 58 467.1371429 456.6757094 436 474
100729 11 335.7633333 342.496675 323 366 671824 408 1343.648 1346.386064 1323 1363 331598 696 473.7114286 473.5814235 448 506
179780 184 599.2666667 635.5666821 611 659
Just so people are aware, I appear to have upset phoodoo who states he is withdrawing from future participation here.. Any helpful feedback appreciated in the moderation thread.
I’ve been catching up on the past few days’ conversations here and, while I agree with Prof. Felsenstein that the discussion of the definition of “generation” is a red herring distracting from the core point of the model, I thought I’d spend a slightly long lunch providing phoodoo with the data he requested. Accordingly, here are the results of 1000 trials with populations of 1000 members and 100,000 deaths from start to end:
Population size: 1000
Death limit: 100000
Number of trials: 1000
Generations
Death metric: 100.0
Average metric
Mean: 100.09578
Standard deviation: 3.0364206
Minimum: 53
Maximum: 145
Mean minimum: 75.915
Mean maximum: 124.46
Replacement metric
Mean: 87.956
Standard deviation: 3.707029
Offspring
Mean: 0.99716014
Standard deviation: 0.03046994
Minimum: 0
Maximum: 21
Mean minimum: 0.0
Mean maximum: 10.35
I’m not sure my implementation of the replacement metric that olegt described is accurate, but it’s the least important result.
The average of Prof. Felsenstein’s generation measurement is very close to # of deaths / N over 1000 trials, with a fairly small standard deviation. It typically falls between 75% and 125% of the other metric.
The average number of offspring hovers right around 1, with an average maximum of just over 10.
Overall, this seems to support the idea that this model, while very simple, doesn’t suffer from bizarre behavior due to outliers in the vast majority of trials.
The code is available at http://www.softwarematters.org/src/mandm.lisp. It could do with some optimization.
Very nice, Patrick!
What fraction did you use in the replacement metric? In other words, how much of the population would have to be replaced?
Patrick,
Thanks Patrick. Just to note to phoodoo, I was not (just) being arsey in not immediately responding to your call for data. The version in question was at home; I was talking from work. And now I’m off for a run, then a drink with mates, then playing guitar in a pub, then work again … yes, I’m sure you’re fascinated by my life. 😉 Patience, patience!
For that run I used your suggested 90%. However, I wasn’t sure how you calculate that. The value listed is calculated by sorting the generation numbers for each member of the population, dropping the smallest 10%, and returning the minimum from those remaining.
I’m interested in how you calculate it.
As much as I like hacking Lisp, your afternoon sounds like more fun!
Patrick,
Mmmmmmm. LISP! [/Homer]
I thought phoodoo might be cranky because he was being offered VBA code, so I wrote my version in a Real Programming Language ™.
Phhhfffft, Patrick. Its all Julia these days.
So it’s true! I had never heard of Julia (well, the programming language) until very recently — shock, horror! — I read that Douglas Bates, author of the lme4 R package, is switching from R to Julia.
More proof that “modern” programming languages continue to asymptotically approach the capabilities of Lisp. 😉
You mean I have to give up FOTRAN II ?
and not write things like this:
20 READ INPUT TAPE 5, …
You had tapes? You were spoilt. Back doing the tiny amount of computer programming deemed necessary when I was an undergrad, we wrote code (in fortran – were there Do LOOPs? it’s been a while) on ordinary paper, handed it in to human compilers who produced punched cards to run on the mainframe. I remember thinking, this’ll never catch on!
You didn’t punch your own cards? Luxury.
petrushka,
LOL
Bet I could still knock off a pretty good drum card…
petrushka and Alan Fox,
Of course I punched my own cards. I still have quite a few cards. I took my first computer programming course in 1961 on the CDC 1604 at the University of Wisconsin. For that class they would not let all of us near the card punches so a staff member punched them from forms we filled out. But later I punched lots of my own. The READ INPUT TAPE was for the computer to read data off the tape, but we supplied the punched cards and they transferred that to tape.
In the second session of the class they announced that they had just got the assembler working, so we didn’t have to type 012 for clear-and-add, and now we had the luxury of typing CLA instead.
A course? Luxury.
Patrick,
Oi! I can still hear you, you know! At least it’s portable …
[Mumble mutter bloody language snobs. Good job I didn’t offer up my COBOL version!]
I made a decent, but not fantastic living in programming. I had exactly seven days of formal training. Five in a language called DIBOL, which was a DEC version of COBOL. With some proprietary weirdness. All integer math. Never used it.
I had two days of training in Visual Basic around 1994. I had never seen a Windows machine and spent most of the time figuring out how to navigate.
My first job was in COBOL, which I learned from the IBM COBOL language reference. That was a CICS shop, so my very first programming job was client/server, not entirely unlike web programming. A few years later I learned C from K&R. I eventualy did a bit of Visual BASIC, but never got proficient. I had to finish a rather massive “object oriented” database conversion program abandoned by its originator.
I find it ironic that my last big programming project mirrored my first. I was supposed to generate 80 byte punch card images from a SQL database. Not just generate the transactions,. but validate them by applying the rules taken from the entire set of federal mortgage regulations. That was the same as my first job, except the earlier one took the data directly from user input.
If you have a mortgage, the management software is almost certainly still running on a mainframe crunching 80 byte card images.
Old computers aside, did anyone ever figure out what the point of the comments by “phoodoo” really was? Something like this:
1. My definition of generation time is better than yours, and
2. Your stochastic process modeling genetic drift isn’t realistic enough, and
3. Therefore you can’t show that “Chance” can fix alleles.
For that matter what was the point of Barry A’s insistence on calling natural selection a “Chance” mechanism? Why does it matter what label we give it?
The only advantage to him I can see from labeling it that way was that then he could turn around and assure onlookers that natural selection was a theory that adaptations arose “purely by chance”. Which would just be misleading propaganda.
Or am I accusing him of something base and ignoble, because I am missing some bigger and more serious reason? Is it perhaps something to do with the Design Inference and ruling out “chance”?
It never made sense to me.
I think he was looking for a way to disregard the results of the modeling. But I’m not sure why. The model should be just as valid for the creationist as for the evolutionist. And, at least in my opinion, the results ought to be as interesting to the creationist as they are to the evolutionist.
I don’t think any creationists have claimed that genetic drift doesn’t occur. What they originally really wanted to do was claim that natural selection couldn’t explain why organisms have adaptations. Nowadays they tend instead to claim that natural selection plus mutation can’t explain “novel” adaptations, where “novel” is a flexible definition, by having it only apply to “macroevolution”, itself a movable goalpost. Other adaptations are dismissed as merely microevolution, which they say no one questions.
However I have noticed that when “mere” microevolution is being discussed, any attempt to get them to admit that adaptations there can be explained by natural selection plus mutation actually ends up meeting a lot of resistance.
You’re overthinking this. YECs don’t give a damn about internal consistency; all they care about is that Evolution Is Wrong. As long as Assertion X can be painted up to seem like it supports the proposition that Evolution Is Wrong, a YEC will happily make Assertion X—even if they’ve earlier made a different Assertion Y which contradicts the present Assertion X. Because Evolution Is Wrong, and that’s all there is to it. YECs can typically learn to understand just about any scientific concept, provided that they don’t realize that the concept actually supports evolution. But once the YEC realizes that whatever-it-is really does make it look like evolution is correct, they will shift mental gears and vehemently argue against the concept they formerly found unobjectionable… or perhaps just raise vehemently argue that the concept in question doesn’t support evolution no way nohow no nuh-uh.
Because Evolution Is Wrong. Which means that anything that’s Right, cannot support evolution.
I think phoodoo was hoping that too many generations would elapse ‘in reality’ for this to be a relevant model, so if you make ‘generation’ something more discrete than the conventional take on it, but just as long, and stack them serially (like computed versions typically do), and perhaps find out that the model only works if some individuals are immortal, or have unfeasibly large numbers of offspring … the meta is interesting, and demonstrates further why debating Creationists can only be regarded as a leisure activity with no goal beyond that – an outcome of the “I hadn’t thought of it that way” type is almost never achieved, or at least never voiced. I’m sure they feel the same way.
Although I myself once had more reservations than I currently do about the relevance of population genetics to ‘real’ situations. My position changed through debate.
Allan Miller,
Population genetics shows, very broadly, that many different models with overlapping or discrete generations all behave the same, once you compare cases with equal effective population number. That does involve figuring out what generation time is for the models with overlapping generations. And the correct way to do that is, of course, the way most of us have been doing it.
It was therefore a vain hope on phoodoo’s part that the M&M model would be found to somehow behave differently from others. Phoodoo’s bizarre private definition of generation time would not have made any difference — we’d simply find that you needed to equate 100 of phoodoo’s “generations” to one of everyone else’s, and then the M&M model would show the same genetic drift behavior as other models.
My own reservations about population genetics are based entirely on the difficulty I have following the math. Phoodoo’s Simplicio has forced what is to me a worthwhile discussion. I particularly appreciate the animation.
Since I have invested more time on a neat presentation than phoodoo’s patience and presently uncertain ongoing status really merit, here is a quick textual version of 2 parameters which could depart wildly from a ‘real’ population in a significant manner. They don’t.
Age at death
Offspring Number
N=10,000
Average age at death,
using the steady tick of birth/death as a timer: N birth/death events.
This is pretty much as you’d expect – the population is at steady state, so N individuals, each having a chance of dying of 1/N per ‘tick’, will indeed on average die once every N ticks! Because N is quite large, and there are N^2 ticks, there is very little variance in this value.
Maximum age at death – between 14N and 21N bdes over 10 runs. That is, if N events take a year, the oldest individuals vary from 14 to 21 in that sample of runs. So, given an average increment per ancestor of 1 new generation per N births, it is possible for occasional individuals to still be giving birth while very much later generations are also. But it is not necessary for the behaviour of the model that such individuals exist. I don’t see any great change arising if a cap on age were introduced – these organisms don’t die of old age, but they still die from living too long! The behaviour – fixation – occurs in every single run. It is the only way to halt any given iteration, and they have all halted.
Offspring Number follows a similar distribution – the count for each incremental value is approximately the sum of all those for greater values – that is, half the population dies without giving birth, a quarter after 1 offspring, an eighth after 2 … the maximum therefore contributes little to the main behaviour, which comes from the lower counts. 1 run of 10 had 32 as the max, 2 had the next greater of 26, but you don’t get much of a fraction with more than about 20. These are not outrageous figures.
(This population may appear ridiculous because you can breed as soon as you are born until the day you die, but perhaps one could almost regard it as the effective (breeding) portion of a larger population in which juveniles and the superannuated exist but are simply not counted – they are only counted in this one while they are fertile. No matter.)
Joe Felsenstein,
One area where I find population genetics to have been misleading is in the matter of the “twofold cost of sex”. I think it’s an illusion, though I have found myself in phoodoo’s position, the scorned outsider, when trying to defend that. It’s a complicated argument, but I think even such eminent people as Williams, Maynard Smith and Hamilton missed important considerations in their formulation, which still has some scratching their heads over what might be the offsetting “twofold benefit” today. There isn’t one, IMO.
Potentially unmasking myself as a crank, and a matter for another thread, perhaps!
I think that the point has some value. As mutation is a stochastic process, as “chance” is not a cause”, then there are unknow factors that produces them. As we have found specific mechanism for adaptation changes it is still possible that microevolution is a built-in mechanism of the life forms.
There are quite a few known factors too, though it is only germinal mutations that can be inherited.