
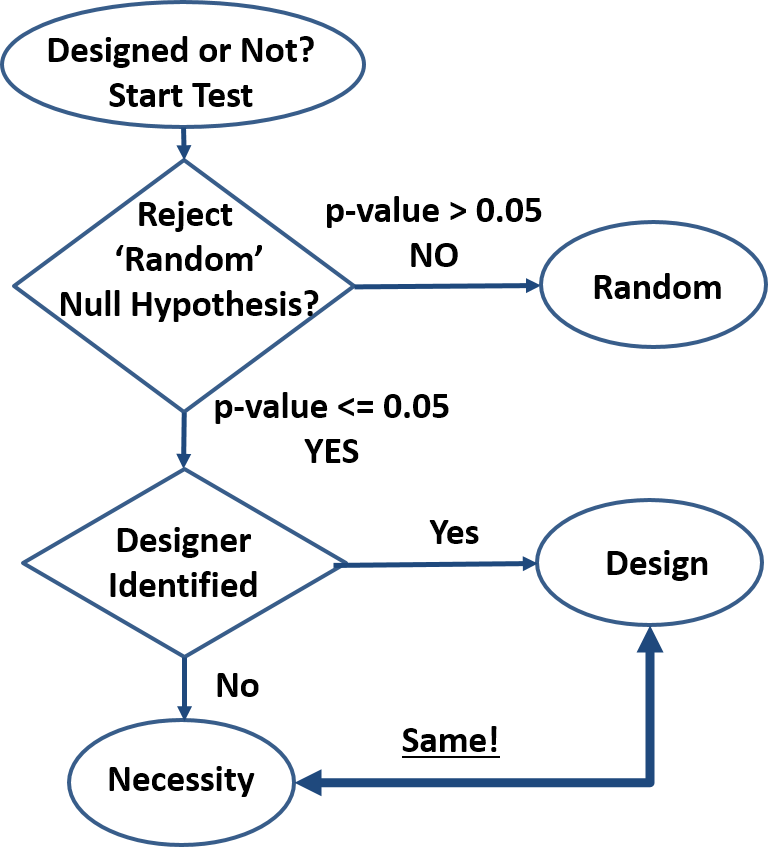
 Design is order imposed on parts of a system. The system is designed even if the order created is minimal (e.g. smearing paint on cave walls) and even if it contains random subsystems. ‘Design’ is inferred only for those parts of the system that reveal the order imposed by the designer. For cave art, we can analyze the paint, the shape of the paint smear, the shape of the wall, composition of the wall, etc. Each one of these separate analyses may result in separate ‘designed’ or ‘not designed’ conclusions. The ‘design’-detection algorithm shown in the attached diagram can be employed to analyze any system desired.
Design is order imposed on parts of a system. The system is designed even if the order created is minimal (e.g. smearing paint on cave walls) and even if it contains random subsystems. ‘Design’ is inferred only for those parts of the system that reveal the order imposed by the designer. For cave art, we can analyze the paint, the shape of the paint smear, the shape of the wall, composition of the wall, etc. Each one of these separate analyses may result in separate ‘designed’ or ‘not designed’ conclusions. The ‘design’-detection algorithm shown in the attached diagram can be employed to analyze any system desired.
- How do we know something is not random? By rejecting the null hypothesis: “the order we see is just an artifact of randomness”. This method is well established and common in many fields of research (first decision block in diagram). If we search for extraterrestrial life, archeological artefacts, geologic events, organic traces, etc., we infer presence based on specific nonrandom patterns. Typical threshold (p-value) is 0.05 meaning “the outcome observed may be due to randomness with a 5% or less probability”. The actual threshold is not critical, as probabilities quickly get extreme. For instance, given a 10-bit outcome (10 coin toss set), the probability of that outcome being random yet matching a predetermined sequence is 0.1%, well below the 5% threshold. A quick glance at biological systems show extreme precision repeated over and over again and indicating essentially zero probability of system-level randomness. Kidneys and all other organs are not random, reproduction is not random, cell structure is not random, behavior is not random, etc.
- Is a nonrandom feature caused by design or by necessity? Once randomness has been excluded, the system analyzed must be either designed as in “created by an intelligent being”, or a product of necessity as in “dictated by the physical/scientific laws”. Currently (second decision block in diagram), a design inference is made when potential human/animal designers can be identified, and a ‘necessity’ inference is made in all other cases, even when there is no known necessity mechanism (no scientific laws responsible). This design detection method is circumstantial hence flawed, and may be improved only if a clearer distinction between design and necessity is possible. For instance, the DNA-to-Protein algorithm can be written into software that all would recognize as designed when presented under any other form than having been observed in a cell. But when revealed that this code has been discovered in a cell, dogmatic allegiances kick in and those so inclined start claiming that this code is not designed despite not being able to identify any alternative ‘necessity’ scenario.
- Design is just a set of ‘laws’, making the design-vs-necessity distinction impossible. Any design is defined by a set of rules (‘laws’) that the creator imposes on the creation. This is true for termite mounds, beaver dams, beehives, and human-anything from pencils to operating systems. Product specifications describe the rules the product must follow to be acceptable to customers, software is a set of behavior rules obeyed, and art is the sum of rules by which we can identify the artist, or at least the master’s style. When we reverse-engineer a product, we try to determine its rules – the same way we reverse-engineer nature to understand the scientific laws. And when new observations infirm the old product laws, we re-write them the same way we re-write the scientific laws when appropriate (e.g. Newton’s laws scope change). Design rules have the same exact properties as scientific laws with the arbitrary distinction that they are expected to be limited in space and time, whereas scientific laws are expected to be universal. For instance, to the laboratory animals, the human designed rules of the laboratory are no different than the scientific laws they experience. Being confined to their environment, they cannot verify the universality of the scientific laws, and neither can we since we are also confined in space and time for the foreseeable future.
- Necessity is Design to the best of our knowledge. We have seen how design creates necessity (a set of ‘laws’). We have never confirmed necessity without a designer. We have seen that the design-necessity distinction is currently arbitrarily based on the identification of a designer of a particular design and on the expectation of universality of the scientific laws (necessity). Finally, we can see that natural designs cannot be explained by the sum of the scientific laws these designs obey. This is true for cosmology (galaxies/stars/planets), to geology (sand dunes/mountains/continents), weather (clouds/climate/hydrology), biology (molecules/cells/tissues/organisms), and any other natural design out there.
- Scientific laws are unknowable. Only instances of these laws are known with any certainty. Mathematics is necessary but insufficient to determine the laws of physics and furthermore the laws of chemistry, biology, behavior, etc., meaning each of the narrower scientific laws has to be backwards compatible with the broader laws but does not derive from the more general laws. Aside from mathematics that do not depend on observations of nature, the ‘eternal’ and ‘universal’ attributes attached to the scientific laws are justified only as simplifying working assumptions, yet too often these are incorrectly taken as indisputable truths. Any confirming observation of a scientific law is nothing more than another instance that reinforces our mental model. But we will never know the actual laws, no matter how many observations we make. Conversely, a single contrary observation is enough to invalidate (or at least shake up) our model as happened historically with many of the scientific laws hypothesized.
- “One Designer” hypothesis is much more parsimonious compared to a sum of disparate and many unknown laws, particles, and “random” events. Since the only confirmed source of regularity (aka rules or laws) in nature is intelligence, it takes a much greater leap of faith to declare design a product of a zoo of laws, particles, and random events than of intelligence. Furthermore, since laws and particles are presumably ‘eternal’ and ‘universal’, randomness would be the only differentiator of designs. But “design by randomness” explanation is utterly inadequate especially in biology where randomness has not shown a capacity to generate design-like features in experiment after experiment. The non-random (how is it possible?) phantasm called “natural selection” fares no better as “natural selection” is not a necessity and in any case would not be a differentiator. Furthermore, complex machines such as the circulatory, digestive, etc. system in many organisms cannot be found in the nonliving with one exception: those designed by humans. So-called “convergent evolution”, the design similarity of supposedly unrelated organisms also confirms the ‘common design’ hypothesis.
- How does this proposed Intelligent Design Detection Method improve Dembski’s Explanatory Filter? The proposed filter is simpler, uncontroversial
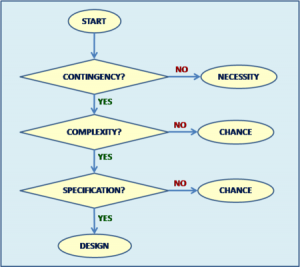 with the likely [important] exception of equating necessity with design, and is not dependent on vague concepts like “complexity”, “specification”, and “contingency”. Attempts to quantify “specified complexity” by estimating ”functional information” help clarify Dembski’s Explanatory Filter, but still fall short because design needs not implement a function (e.g. art) while ‘the function’ is arbitrary as are the ‘target space’, ‘search space’, and ‘threshold’. Furthermore, ID opponents can easily counter the functional information argument with the claim that the ‘functional islands’ are linked by yet unknown, uncreated, eternal and universal scientific laws so that “evolution” jumps from island to island effectively reducing the search space from a ‘vast ocean’ to a manageable size.
with the likely [important] exception of equating necessity with design, and is not dependent on vague concepts like “complexity”, “specification”, and “contingency”. Attempts to quantify “specified complexity” by estimating ”functional information” help clarify Dembski’s Explanatory Filter, but still fall short because design needs not implement a function (e.g. art) while ‘the function’ is arbitrary as are the ‘target space’, ‘search space’, and ‘threshold’. Furthermore, ID opponents can easily counter the functional information argument with the claim that the ‘functional islands’ are linked by yet unknown, uncreated, eternal and universal scientific laws so that “evolution” jumps from island to island effectively reducing the search space from a ‘vast ocean’ to a manageable size.
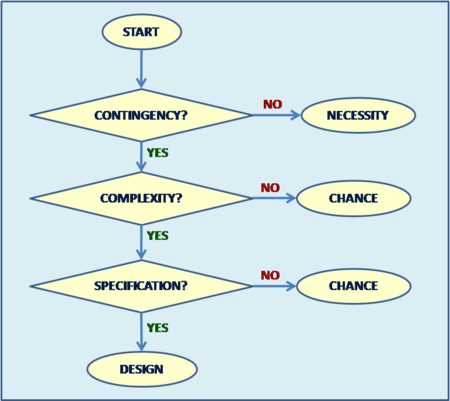
Summary
- Design is order imposed on parts of a system
- A system is nonrandom if we reject the null hypothesis: “the order we see is just an artifact of randomness”
- Current design detection method based on identifying the designer is circumstantial hence flawed
- Design is just a set of ‘laws’, making the design-vs-necessity distinction impossible
- Necessity is Design to the best of our knowledge
- Scientific laws are unknowable. Only instances of these laws are known with any certainty
- “One Designer” hypothesis is much more parsimonious compared to a sum of disparate and many unknown laws, particles, and “random” events
- This Intelligent Design Detection Method improves on Dembski’s Explanatory Filter
Pro-Con Notes
Con: Everything is explained by the Big Bang singularity, therefore we don’t need Intelligent Design.
Pro: How can a point of disruption where all our knowledge completely breaks down explain anything? To the best of our knowledge, Intelligent Design is responsible for that singularity and more.
Probably not. In any case, it’s not my thing.
Gambling is well understood by behavioral psychologists.
Charts, graphs, whatever you want. Unfortunately, most of the best researchers work for the gaming industry and have no incentive to share their knowledge.
To quote Jane Austen, “I am obliged for your condescension”.
Yes, that is exactly what I mean. But you continue to ignore the import of what I have said. We expect that the real sample will diverge from theory (it is unlikely that we will see exactly the predicted number of 17s in any set of lottery results). The question is whether it diverges so much as to make our null hypothesis unrealistically improbable. So we apply an objective test and draw a conclusion from the results.
I have no idea what that means.
Expected. And more than it should be. Also unexpected. Even when its ONE number off.
Keep digging.
Yes, keep digging. It isn’t whether the real sample varies from the theoretical (we expect it will). It is by how much it varies, and only statistics can tell you whether you should reliably depend on the result.
One.
You already said so.
That is more “than it should be”.
Mate, it is a simple calculation to answer your question, you have the sample size (N=10,000), you have the expected value (1500), you have the observed result (I found it in my notes: 1632 instances of the number 17 in the 10,000 actual lottery results).
Now go away and calculate whether we should say that this result is either:
1. A result of random chance; or
2. An underlying bias in the lottery system
It is pretty simple really, but make sure you use the correct statistical test (hint: the test has two tails).
I didn’t ask this question.
I said how far off does it have to be to be considered too much or too little. You said ONE.
I said it quite clearly. You are obfuscating now.
That is exactly what my test addresses. Go and do the test and tell us what your results are.
You are saying it is not true that “the number 17 has turned up more often than it should have.”
I agree that could lead to confusion.
As in, the election of senators is biased?
Some good explanations of statistics, guys. Thank you.
Do you have senators in your country? We have senators in my country and the method of selection is definitely biassed.
I know the odds of various rolls of a pair of dice. I understand that the casino does not give “fair odds” on bets on rolls of the dice. I can calculate how much I can expect to lose over the long run. But I know there are short term deviations where certain numbers may come up more often than others.
Should I play dice?
How often can I expect to observer one of these short term deviations from the mean and would I recognize it if I saw it?
With four heads I could look surprised, worried, ambivalent, and grumpy all at the same time!
You will observe these short-term variations from “randomness” all the time. But you won’t be able to predict when they will happen so that you can take advantage of them.
That is why you should never bet.
That’s outside the 99% confidence interval, isn’t it? I downloaded a binomial distribution spreadsheet to calculate that. The probability of the interval [1368, 1632] is 0.99979211. So the probability that at least one number is outside of that range is 0.99979211^40=0.9917180. That starts looking statistically significant to me. What am I missing now please?
😀 😀 😀 😀
I never asked what you test address. You are running around the point like a drunken crow.
ANY deviation, even if by ONE, from the EXACT expected value is too little or too much by definition, according to you.
That is the point, and not any of the other misdirections you are trying to throw out there.
I am saying, by his own definitions, EVERY number has come up either more or less than it should have.
No, it’s not. Larger deviations from the mean are less probable than small ones. Obviously.
If you won’t accept the definitions provided then you’ll continue to miss the point. I know that with ID you are used to defining words however you like.
No, you’re not listening. That the expected value is 100 doesn’t mean that one expects to get exactly 100.
Unless its the exact expected value, according to him, then it must be more or less than it should be. You are not listening.
I edited my previous post. You still don’t get it, that’s not what expected value means. For the empteenth time, the expected value is just the average, we would only expect to get the expected value after an infinite number of repetitions
Don’t try to put words into Timothy’s mouth. Go back and read the exchange, you seem to be struggling with what was written.
ONE different from the exact expected value . I asked clearly, he answered clearly. He can walk it back if he wants, but its there in simple English.
If your side struggles with the most basic of wording, higher level concepts are going to be quite a challenge.
I’ll just note the irony of reading this coming from a person who has problems with the concept of natural selection. Or isolation. Or speciation.
Or the word “ should” .
You don’t understand the concept of natural selection? Or isolation? Or speciation.
Well, don’t worry, most evolutionists don’t. They may understand isolation I suppose.
Dazz
“That’s outside the 99% confidence interval, isn’t it? I downloaded a binomial distribution spreadsheet to calculate that. The probability of the interval [1368, 1632] is 0.99979211. So the probability that at least one number is outside of that range is 0.99979211^40=0.9917180. That starts looking statistically significant to me. What am I missing now please?
Ackk..I mistyped – should have been 1532. But even would be significant. Why did you use a binomial distribution? I would expect the results of repeated sampling fo.distribute normally.
Ah, thanks, that’s a whole nother story. Or do you mean 1532 would still be significant?
Oh, just because I’m extremely rusty. A quick google search refreshed my memory. So we can approximate the binomial distribution to a normal one:
µ=np; µ=10000*0.15 = 1500 …as “expected” (in the colloquial sense, phoodoo, so don’t get your knickers in a bunch now)
σ²=np(1-p) = 10000*0.15(0.85) = 1275
So the std dev σ is the square root of the variance (1275).
σ=35.7
So the P(x not in[1468,1532]) = 0.3701 (ETA, had to edit the notation, apparently the Latex plugin was removing characters)
That doesn’t look significant, does it? unless you were set to look specifically at number 17 beforehand, and even then a 37% doesn’t seem conclusive at all, but then again, I’m not sure I’m doing this right
The test is two-tailed isn’t it? So I think my original interpretation stands up.
Sorry Tim, I don’t follow. Your original interpretation was that the deviation for number 17 wasn’t statistically significant, and at 1532 appearances I agree with that. Are we maybe talking past each other? Also, was a two tailed test the wrong choice?
If the two-tailed test confirms the null hypothesis (not much statistical significance) wouldn’t a one-tailed test be unnecessary?
And yet more than it should be….
derp
There’s always a mix of of ORDER and [what looks like, but is observational unknowable] RANDOMNESS. The point of this OP is to detect Design by first detecting ORDER. And that’s what the example showed (and you finally agreed!). It’s true, but irrelevant that some randomness is additive to order.
Design detection is when you follow the decision tree beyond the first decision block …that you know accept, right?
Stochastic is not necessarily random. Market prices are stochastic, but not random as people set prices based on something: sentiment, news, etc. Not randomly.
Randomly in the sense of not predictable.
So your entire paragraph #2 is a rather involved way of saying that we start off with a pattern? OK, that seems a reasonable start to detect design.
What Alan said: if you can’t predict it, it doesn’t matter.
Also: you are using “random” in a different way now: Market prices are not uniformly distributed.
Is predictable the same thing as algorithmic in your view?
IOW is it possible that something can be predicted but not in a rigid X plus Y yields Z way?
peace
Well, okay, you actually asked Alan.
If a system is predictable, we are probably using algorithms to make the predictions. But there is no reason to believe that the system itself is using the same algorithms. And there is no reason to believe that the system is even using any algorithms at all.
As I am sure you know, even if the system has stochastic components, as long as these can be modeled we can still make predictions, with QM being the standard example.
That fact about models with stochastic components confuses many, IMHO.
(Of course, there is also the science-via-dictionary argument about the meaning of ‘stochastic’ versus ‘random’, if one wants to add to the confusion rather than understand the science).
I haven’t seen any cogent argument that it matters whether mutations are targeted toward “designed” goals or not.
New sequences still have to survive the gauntlets of purifying selection, positive selection, and drift.
The notion that designed mutations are inserted by poof or by program seems to be incompatible with all the jabber about mutations being mostly detrimental, and genomes melting down.
I say evolution is chance based and people think by that I meant to say that evolution is random. They don’t seem to understand the difference even if they do understand the science. So perhaps a dictionary is appropriate.
I think there is a fundamental issue with people thinking they can understand science by looking at ordinary language popularizations (or their Youtube versions). But to understand the science you have to:
1. Understand the underlying math. This can involve info theory, probability distribution, statistical inference for the biology one sees here and of course calculus and linear algebra for basic physics.
2. Understand how a scientific model uses the math.
3. Understand how the model is used to make and empirically test predictions or retrodictions (possibly this might involve simulation).
4. Understand how scientists use IBE to assess the model based on the tests.
A lot of what one sees on these forums is people trying to make deductive arguments from propositional logic attempts to formalize the popularizations. That’s lots of fun on forums but it’s not an effective way to understand the science.
Can we predict using no algorithms at all?
For example I predict that no minds will be changed by this conversation when it comes to design detection.
1) Did I use an algorithm to make that prediction?
2) If not does it mean that the changing of minds is a random process?
peace
Can you make no predictions at all about a system that you can’t model?
Do I need to be able to “model” the behavior of intelligent agent(s) in order to make predictions about that behavior?
peace
“Popullarizations” are merely attempts at summarizing the science in a way to enhance understanding.
IMO If you can’t formalize a “popularization” using logic then folks should quit using it and look for ones that work. If scientists can’t “popularize” their theories so that others can understand them then the theories are not much real use to the public.
peace
peace
I’ll bet the folks genetically engineering crops and livestock would take issue with the contention that their life’s work does not matter because they still have to “survive the gauntlets of purifying selection, positive selection, and drift.”
peace
I say evolution is accidental, and the evolutionists have apoplectic seizures.