
Jonathan Bartlett, known here as JohnnyB, has written a very thought-provoking post titled, A New View of Irreducible Complexity. I was going to respond in a comment on his post, but I soon realized that I would be able to express my thoughts much more clearly if I composed a post of my own, discussing the points which he raises.
Before I continue, I would like to say that while I find JohnnyB’s argument problematic on several counts, I greatly appreciate the intellectual effort that went into the making of his slide presentation. I would also like to commend JohnnyB on his mathematical rigor, which has helped illuminate the key issues.
Without further ado, I’d like to focus on some of the key slides in JohnnyB’s talk (shown in blue), and offer my comments on each of them. By the time I’m done, readers will be able to form their own assessment of the merits of JohnnyB’s argument.
Part One: What is JohnnyB trying to show?
Goals
Create a definition of Irreducible Complexity which shows that Darwinism is logically impossible over a wide range of assumptions.
Show the conditions for which evolution may or may not be possible…
[snip]
My Comments:
1. JohnnyB has set the bar very high here. He aims to show that a Darwinistic explanation of Irreducible Complexity is not merely vanishingly improbable, but logically impossible, like the term “married bachelor.” If he can do that, I’ll be very impressed. Not even Michael Behe claimed to be able to demonstrate this.
2. Right at the outset, JohnnyB assumes that the only good naturalistic explanation of Irreducible Complexity is a Darwinian one. That is Professor Richard Dawkins’ view, as JohnnyB points out later on in his talk. However, not all biologists agree with Dawkins.
Professor Larry Moran is a biochemist and a long-standing advocate of random genetic drift as the dominant mechanism of evolution. In a post titled, Constructive Neutral Evolution (CNE) (September 6, 2015), Moran goes further. Drawing on the work of Arlin Soltzfus, Michael Gray, Ford Doolittle, Michael Lynch, and Julius Lukes et al., Moran argues that non-adaptive mechanisms can account for the evolution of irreducibly complex systems. He illustrates his point with a simple hypothetical scenario (see here for a diagram):
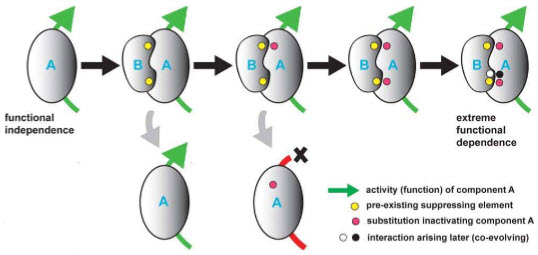{kind=link}
Imagine an enzyme “A” that catalyzes a biochemical reaction as a single polypeptide chain. This enzyme binds protein “B” by accident in one particular species. That is, there is an interaction between A and B through fortuitous mutations on the surface of the two proteins. (Such interactions are common as confirmed by protein interaction databases.) The new heterodimer (two different subunits) doesn’t affect the activity of enzyme A. Since this interaction is neutral with respect to survival and reproduction, it could spread through the population by chance.
Over time, enzyme A might acquire additional mutations such that if the subunits were now separated the enzyme would no longer function (red dots). These mutations would be deleterious if there was no A + B complex but in the presence of such a complex the mutations are neutral and they could spread in the population by random genetic drift. Now protein B is necessary to suppress these new mutations making the heterodimer (A + B) irreducibly complex. Note that there was no selection for complexity — it happened by chance.
Further mutations might make the interaction more essential and make the two subunits more dependent on one another. This is a perfectly reasonable scenario for the evolution of irreducible complexity. Anyone who claims that the very existence of irreducibly complexity means that a structure could not have evolved is wrong. (Emphases mine – VJT.)
Throughout his talk, JohnnyB assumes that the evolution of irreducibly complex systems by chance processes is fantastically improbable. Perhaps this assumption is false. If it is, then his proof of the impossibility of irreducibly complex systems arising via unguided processes fails.
************************************************************************************************
Part Two: Evolution and computation

A Universal Turing machine U. U consists of a set of instructions in the table that can “execute” the correctly-formulated “code number” of any arbitrary Turing machine 
The following three slides from JohnnyB’s talk explain how he links Darwinian evolution to computation theory.
Why Computability Theory?
Evolution is, at its core, a statement about mapping changes in genotypes to changes in phenotypes.
In other words, there is a code which performs a function, and the change in code produces a change in function.
The mathematics developed to understand the relationship between codes and functions at a fundamental level is computability theory.
—————————————————————————————–
Turing’s Theory of Computation
All known paradigms of computation are reducible to Turing machines.
[snip]
—————————————————————————————–
Universal vs. Special Machines
A Turing machine is said to be a Universal machine if it can compute any computable function just by changing its tape.
Every Universal machine is equally powerful.
A non-universal Machine will only be able to implement a subset of computable functions.
If the set of needed functions is not known ahead of time, one must use a Universal machine.
Therefore, if biology is to evolve to environments it isn’t aware of ahead-of-time, then the proper mathematical model is the Universal machine.
My Comments:
1. It is very important to understand what the foregoing argument shows. It doesn’t show that evolution itself is a kind of computation. Nor does it imply that the biosphere is some sort of Universal Turing machine, which generated the dazzling variety of life-forms existing on Earth today.
Rather, what the argument purports to show is that if scientists want to model how evolution works – and in particular, how it can generate new functions without knowing in advance which ones it might be called upon to produce – then they will have to construct a Universal Turing machine, in order to do the job.
2. Does the argument even prove this much? I think not. All it shows is that if you want to explain how natural selection can generate any function, without knowing in advance which one it will be required to create in a given environment, then you will need a Universal Turing machine. But biologists don’t believe that natural selection can generate any function. What they believe is that it can generate some functions, where “some” might well mean: a vanishingly small fraction of the range of all possible functions that could enhance an organism’s fitness in some situations. I made the same point in my review of Dr. Douglas Axe’s book, Undeniable, where I wrote:
Finally, even if Axe’s argument purporting to show that accidental inventions are fantastically improbable were valid, it would still only apply to accidental inventions in general. A much stronger argument is needed to show that each and every accidental invention is fantastically improbable. By definition, the inventions generated by a blind evolutionary process will tend to be the ones whose emergence is most likely: the creme de la creme, which make up only a tiny proportion of all evolutionary targets. For these targets, the likelihood of success may be very low, but not fantastically improbable.
Next, JohnnyB, drawing upon the work of mathematician Stephen Wolfram, introduces a few useful definitions, which distinguish between four different classes of Universal Turing machines:
Stephen Wolfram’s Complexity Classes
Stephen Wolfram classified Turing machines into the following four classes:
Class 1 [Turing] machines [are machines that] tendsed to converge on a single result, no matter what the initial conditions.
Class 2 [Turing] machines [are machines that] give relatively simple and predictable results…
Class 3 [Turing] machines [are machines that give] results that are individually unpredictable, but statistically predictable.
Class 4 [Turing machines are machines that give] results that are not predictable either individually or statistically….
Class 4 systems are the only systems in which Universal computation can occur.
(N.B. Words in brackets were added by me, as a paraphrase of what JohnnyB was saying. Words in blue appear on JohnnyB’s slide, at 15:36 – VJT.)
My Comments:
UPDATE: In a comment below, Tom English has pointed out a serious mistake in the slide above. Readers will note that JohnnyB states that Wolfram classified Turing machines into four classes. This is factually incorrect. Wolfram’s classification is of cellular automata, not Turing machines. Readers can confirm this by consulting this article on cellular automata in the Stanford Encyclopedia of Philosophy – something I should have done myself. I would like to thank Tom English for his correction.
I think the perceptive reader will be able to see where JohnnyB is going here. He’s going to argue that if scientists want to model evolution by natural selection, they’ll have to rely on the most chaotic kind of Universal Turing machines: Class 4 machines, whose results are radically unpredictable.
And now, at last, we come to the nub of JohnnyB’s argument. The numbering below is mine, not JohnnyB’s.
************************************************************************************************
Part Three: JohnnyB’s proof that natural selection is incapable of accounting for Irreducible Complexity

Visualization of a population evolving in a static fitness landscape. Image courtesy of Randy Olson and Bjørn Østman, and Wikipedia.
Universality and Natural Selection
1. Increasing the class [of a Turing machine complexity system – VJT] yields more degrees of freedom, but also makes the relationship more chaotic between changes in input and the resulting output.
2. Class 4 systems are the only systems in which Universal computation can occur.
3. Hidden premise identified by VJT: evolution requires Universal computation.
Proof: see the above slide on Universal vs. Special machines.
4. Therefore, if evolution were to occur, it would need a Class 4 complexity system.
5. For natural selection to operate, there has to be a smooth pathway of increasing function.
[N.B. “Smooth” is defined by JohnnyB as: moving in one direction, without any giant chasms – VJT.]
6. Class 4 systems, since they are chaotic (mappings of input changes to behavior changes are chaotic), cannot in principle supply such a smooth pathway.
7. Thus, the two requirements for evolution – evolution across Universal computation and a selectable pathway – are mutually incompatible.
My Comments:
1. When I looked at this slide, I realized that there was an unstated premise, which I inserted (premise 3). The wording is very important here: in premise 4, JohnnyB states that if evolution were to occur, it would need a Class 4 complexity system. This statement only makes sense if evolution itself is viewed as a computation, and a universal one at that. But as I argued above in Part Two (comment 1), JohnnyB hasn’t shown that. All he’s shown is that if scientists want to model how evolution could give rise to any kind of function, they’ll need a Class 4 Universal Turing machine for the job. That’s what premise 4 should say.
2. Premise 5 simply restates a point commonly made by Intelligent Design advocates: that evolution by natural selection won’t work unless we have a smooth fitness landscape. This requirement sounds very ad hoc, given that we can readily conceive of countless ways in which a fitness landscape might be so rugged as to render evolution by natural selection impossible. So are evolutionists begging the question by assuming that fitness landscapes are smooth, in the real world? Not at all. Professor Joe Felsenstein explains why in a widely quoted post critiquing a talk given by Dr. William Dembski on August 14, 2014, at the Computations in Science Seminar at the University of Chicago, titled, “Conservation of Information in Evolutionary Search.” Felsenstein writes:
Given that there is a random association of genotypes and fitnesses, Dembski is right to assert that it is very hard to make much progress in evolution. The fitness surface is a “white noise” surface that has a vast number of very sharp peaks. Evolution will make progress only until it climbs the nearest peak, and then it will stall. But…
That is a very bad model for real biology, because in that case one mutation is as bad for you as changing all sites in your genome at the same time!
Also, in such a model all parts of the genome interact extremely strongly, much more than they do in real organisms…
…I argue that the ordinary laws of physics actually imply a surface a lot smoother than a random map of sequences to fitnesses. In particular if gene expression is separated in time and space, the genes are much less likely to interact strongly, and the fitness surface will be much smoother than the “white noise” surface.
3. Another point I’d like to make is that evolution doesn’t occur in just two dimensions, but in hundreds of different directions. For this reason, the likelihood of evolution “hitting a wall” beyond which no further improvements can be made is greatly reduced, as computer scientist Mark Chu Carroll noted in a book review published several years ago:
A fitness landscape with two variables forms a three dimensional graph – and in three dimensions, we do frequently see things like hills and valleys. But that’s because a local minimum is the result of an interaction between *only two* variables. In a landscape with 100 dimensions, you *don’t* expect to see such uniformity. You may reach a local maximum in one dimension – but by switching direction, you can find another uphill slope to climb; and when that reaches a maximum, you can find an uphill slope in some *other* direction. High dimensionality means that there are *numerous* directions that you can move within the landscape; and a maximum means that there’s no level or uphill slope in *any* direction.
4. I would also object to Premise 6 in JohnnyB’s argument above. He writes: “Class 4 systems, since they are chaotic (mappings of input changes to behavior changes are chaotic), cannot in principle supply such a smooth pathway.” What he should have said is that Class 4 systems cannot guarantee the existence of a smooth pathway for the evolution of any given function. But all that shows is that some functions (probably the vast majority) will be incapable of evolving. The argument doesn’t show that no smooth pathway exists for any function. I made a similar point in my review of Dr. Douglas Axe’s book, Undeniable:
Axe is perfectly correct in saying that for any given functional hierarchy that we can imagine, most of its components would have been of no benefit earlier on, before the hierarchy had been put together in its present form. But all that proves is that the vast majority of the fantastically large set of possible functional hierarchies never get built in the first place: they are beyond the reach of evolution. If a functional hierarchy was built by evolution, in a series of steps, then by definition, its components must have performed some biologically useful function when the hierarchy had fewer levels than it does now. The functional hierarchies built by evolution are atypical. But that doesn’t make them impossible.
Hence JohnnyB is incorrect when he infers that “the two requirements for evolution – evolution across Universal computation and a selectable pathway – are mutually incompatible.” All his argument shows is that for a large number of possible functions, these two requirements will be incompatible – which means that these functions will never evolve in the first place. But what about the rest?
However, JohnnyB has another ace up his sleeve. As we’ll see, he argues that whenever there is a smooth, non-chaotic pathway which allows a function to evolve, that function can’t be called irreducibly complex, anyway. So it’s still true that irreducibly complex functions could only evolve via a highly unpredictable, chaotic process, making their emergence a practically impossibility.
************************************************************************************************
Part Four: JohnnyB’s Redefinition of Irreducible Complexity, and his Argument for Design

Orson Welles performs a card trick for Carl Sandburg (August 1942). Image courtesy of Wikipedia.
In the argument below, JohnnyB endeavors to show that irreducibly complex systems, properly defined, require an intelligent designer. The numbering below is mine, not JohnnyB’s.
Redefinition of Irreducible Complexity
1. To implement the arbitrary complexity within biology, biological systems must be Class 4 systems.
2. A “hard” problem is a problem for which a solution only exists utilizing the chaotic space of a Class 4 system.
3. If a Class 4 system needs to solve a “hard” problem, it cannot do so by a process of selection, because the chaotic nature of the system will prevent selection from pointing in any specific direction.
4. Therefore, the chance of hitting a correct solution to a “hard” problem is equivalent to that of chance, since selection cannot canalize the results.
[Here’s a short explanation of “canalize,” from the slide titled, “Multilevel Complexity Classes”:
(i) A Class 4 system can be used to create a non-chaotic Class 1 or Class 2 system,for which changes can lead to smoother searches.
(ii) However, this limits the scope of selectable parameters to those which the implemented Class 1 and Class 2 systems operate.
(iii) Thus, we can say that to the extent that evolution occurs, it is parametrized – or “canalized” – VJT.]
5. Information Theory tells us that this will have a difficulty that increases exponentially with the size of the shortest solution.
6. Solutions to “hard” problems can be achieved only if the solution has prior programming which guides either the mutation or the selection through.
7. An Irreducibly Complex system is a system which utilizes (and utilizes necessarily) the chaotic space of a Class 4 system to implement a function.
8. The existence of an Irreducibly Complex system is evidence of design, because design is the only known cause which can navigate the complexity of a Class 4 system to implement functionality.
My Comments:
1. I would criticize the wording of premise 1: “To implement the arbitrary complexity within biology, biological systems must be Class 4 systems.” It should read as follows: “To model the evolution is any kind of function, of any arbitrary level of complexity, scientists must use Class 4 systems.” Once again, JohnnyB is implicitly assuming that the biosphere is a gigantic natural computer, and that evolutionary changes are computations. This only makes sense on a hyper-computationalist view of the world, satirized by the philosopher John Searle in a memorable essay titled, Is the brain a Digital Computer?: “Thus for example the the wall behind my back is right now implementing the Wordstar program, because there is some pattern of molecule movements which is isomorphic with the formal structure of Wordstar.” Against this view, Searle argues that computation is something which is inherently mind-relative:
There is no way you could discover that something is intrinsically a digital computer because the characterization of it as a digital computer is always relative to an observer who assigns a syntactical interpretation to the purely physical features of the system… [T] to say that something is functioning as a computational process is to say something more than that a pattern of physical events is occurring. It requires the assignment of a computational interpretation by some agent.
2. Premise 2 is the critical one in JohnnyB’s argument. He defines a “hard” problem as one that can only be solved within the chaotic space of a Class 4 system, and he goes on to argue in premise 7 that an irreducibly complex system is one whose generation requires the solution of a “hard” problem: “An Irreducibly Complex system is a system which utilizes (and utilizes necessarily) the chaotic space of a Class 4 system to implement a function.” As we’ll see, JohnnyB thinks that only a designer is capable of finding such a solution.
The problem with this approach is that while it may (if the reasoning proves to be correct) establish that intelligent design is required in order to generate irreducibly complex systems, what it does not show is that any such systems actually exist in Nature. Perhaps the bacterial flagellum, for instance, can be solved within a more restricted, non-chaotic space. JohnnyB cannot rule out such a possibility, for he writes that “to the extent that evolution occurs, it is parametrized” – i.e. “canalized.” At least some evolution occurs in Nature. Who is to say, then, that “canalized” evolution could not possibly give rise to a bacterial flagellum, over a period of aeons?
3. Premises 4 and 5 completely undermine the goal of JohnnyB’s presentation. Premise 4 states that “the chance of hitting a correct solution to a ‘hard’ problem is equivalent to that of chance,” and premise 5 adds that the degree of difficulty for a “hard” problem “increases exponentially with the size of the shortest solution.” But in the Goals section at the beginning of his talk, JohnnyB declared that he was trying to “create a definition of Irreducible Complexity which shows that Darwinism is logically impossible over a wide range of assumptions.” There’s a vast philosophical difference between logically impossible and exponentially improbable.
4. I might also add that “chance” and “chaos” are two entirely different concepts. A chaotic system is radically unpredictable; a system whose processes are governed by chance may still be statistically predictable. The reason why I mention this here is that I argued above that random genetic drift might be able to account for the evolution of some irreducibly complex systems. But this chance process, if it took place, would not have been a totally chaotic one. If it had been, then the systems would almost certainly never have evolved in the first place.
5. Premise 6, which says that “hard” problems can only be solved by “prior programming,” does not warrant the conclusion that an Irreducibly Complex system is evidence of design. The fact that design is the only known cause of some irreducibly complex systems (with which we are familiar) does not imply that design is able to create any irreducibly complex system, of an arbitrarily high degree of complexity. For all we know, there might be systems which are beyond the reach of any designer, because they’re too complex for anyone to model. This is important, for as the eminent chemist Professor James Tour points out, in his 2016 talk, The Origin of Life: An Inside Story, life itself is fiendishly complex. And what makes the puzzle of life’s origin all the more baffling is that even if you had a “Dream Team” of brilliant chemists and gave them all the ingredients they wanted, they would still have no idea how to assemble a simple cell. In Tour’s words:
All right, now let’s assemble the Dream Team. We’ve got good professors here, so let’s assemble the Dream Team. Let’s further assume that the world’s top 100 synthetic chemists, top 100 biochemists and top 100 evolutionary biologists combined forces into a limitlessly funded Dream Team. The Dream Team has all the carbohydrates, lipids, amino acids and nucleic acids stored in freezers in their laboratories… All of them are in 100% enantiomer purity. [Let’s] even give the team all the reagents they wish, the most advanced laboratories, and the analytical facilities, and complete scientific literature, and synthetic and natural non-living coupling agents. Mobilize the Dream Team to assemble the building blocks into a living system – nothing complex, just a single cell. The members scratch their heads and walk away, frustrated…
So let’s help the Dream Team out by providing the polymerized forms: polypeptides, all the enzymes they desire, the polysaccharides, DNA and RNA in any sequence they desire, cleanly assembled. The level of sophistication in even the simplest of possible living cells is so chemically complex that we are even more clueless now than with anything discussed regarding prebiotic chemistry or macroevolution. The Dream Team will not know where to start. Moving all this off Earth does not solve the problem, because our physical laws are universal.
You see the problem for the chemists? Welcome to my world. This is what I’m confronted with, every day.
So it seems that we have a Mexican standoff. It seems that JohnnyB would have to agree that the first living cell must have contained one or more irreducibly complex systems. That being the case, its evolution via unguided processes would have been extraordinarily unlikely, if JohnnyB’s argument is successful. But as Professor James Tour points out, our top designers are incapable of creating such a cell, either. So what produced it? We are left without an answer.
************************************************************************************************
Part Five: JohnnyB’s criticisms of Avida
Avida Checklist
Is the programming language of Avida a Class 4 system? Yes.
Do any of the evolved Avida programs require the use of chaotic spaces in the Class 4 system? No.
Therefore, the evolved Avida programs are not Irreducibly complex.
My Comments:
I know very little about Avida, so I’ll keep my comments brief. What I will say is that JohnnyB’s reasoning above sounds quite similar in thought and tone to a piece that Winston Ewert wrote on the subject of Avida, back in 2014:
What Avida demonstrates is that given a gradual slope, Darwinian processes are capable of climbing it. What irreducible complexity claims is that irreducible complex systems are surrounded on all sides by cliffs. Notice the distinction. Avida says that evolution can climb gradual slopes. Irreducible complexity claims that there are no gradual slopes. Avida is about what we can do with the gradual slopes, and irreducibly complexity is about whether or not the slopes exist. Avida provides no evidence that gradual slopes exist, it just assumes that they do. What Avida demonstrates is simply beside the point of the claim of irreducible complexity. (Emphasis mine – VJT.)
Winston Ewert’s statement that “Irreducible complexity claims that there are no gradual slopes” is basically equivalent to JohnnyB’s claim that irreducibly complex systems require the use of chaotic spaces in a Class 4 system. I have critiqued above (see Part Three, comment 2) the claim that evolution requires a smooth fitness landscape, as an argument for design.
Conclusion
As I see it, JohnnyB’s presentation on irreducible complexity, while far more mathematically rigorous than anything I have seen previously in the Intelligent Design literature, suffers from several major problems:
(i) it completely overlooks non-Darwinian naturalistic mechanisms for the evolution of irreducibly complex systems;
(ii) it commits the “pan-computationalist” fallacy, by treating the biosphere itself as if it were one vast computational system, and equates this system with a Class 4 Universal Turing machine, whose outputs (or results) are radically unpredictable (i.e. chaotic);
(iii) all it shows is that scientists would require such a machine, if they wanted to demonstrate that evolution was capable of generating any kind of function, no matter how complex;
(iv) smooth fitness landscapes are a fairly straightforward consequence of physics in our universe, at any rate – and what’s more, since evolution proceeds in not two but hundreds of different directions at once, the likelihood of evolution getting stuck at some local maximum is very low;
(v) in any case, Class 4 systems are not always chaotic in their behavior – which means that there may well be some complex structures in living things that could have evolved as a result of processes occurring outside the “chaotic space” of radical unpredictability;
(vi) arbitrarily redefining “irreducibly complex systems” as those systems whose evolution would have had to take place within the “chaotic space” of a Class 4 system is no way to safeguard the Argument from Design, because one still needs to show that there are any such systems in Nature, and that the systems which ID advocates consider to be designed could only have evolved in a chaotic fashion, if they evolved at all;
(vii) finally, it has not been shown that there exists an Intelligent Designer Who is capable of creating irreducibly complex systems of an arbitrarily high level of complexity – such as we find in even the simplest living cell. As we’ve seen, not even all the world’s scientists working together would have any idea how to create such a cell. As far as we know, then, intelligence is inadequate for the task of creating life. There may, of course, be some Super-Agent that was capable of creating the first life. But the argument from irreducible complexity, taken by itself, gives us no reason to think that.
I would like to conclude by saying that on an intuitive level, I feel the force of the design argument as much as anyone, and I am quite sure that the first cell was in fact designed – as well as many other complex structures we find in Nature. (How they were designed is another question entirely, on which I try to keep an open mind.) But if I am asked whether it has been rigorously demonstrated that the molecular machines we find within the cell were intelligently designed, I would have to answer in the negative. At the present time, I am inclined to think that the best argument for design is a multi-pronged one, which makes use of several converging lines of evidence.
What do readers think of JohnnyB’s argument? Over to you – and JohnnyB!
Thanks Allan. Just read the relevant section of the Wikipedia entry and that appears to be the case. E-Coli only evolved the ability to grow aerobically on citrate in strains that possessed some “potentiating” mutations. I suppose those were neutral mutations.
That doesn’t follow from the brief C.V. you provided. Software developers, particularly web developers, are not renowned for their mathematical abilities. That kind of knowledge simply isn’t required for the job.
You presume too much. I asked for a transcript because I’m of the old school that prefers reading to watching. Based on previous experience with YECs, I am pretty sure that Jonathan is spouting nonsense. It’s easier to identify and refute that in written form.
It’s quicker, too.
🙂
Patrick,
100% agree, easier to copy-paste than transcribe for critique.
The last third of the talk is insufficiently coherent to refute. What others have done is to respond to the earlier two-thirds. I say that it’s wrong to ignore the fact that the “payload” of the presentation is sheer lunacy. By wrong, I mean ethically wrong. We’re addressing an instance of YEC indoctrination — a presentation that Bartlett made to a group of students. We should not be carving out parts of it for our own intellectual delectation.
I’m suppressing particular remarks on the dementedness of Bartlett’s “mathematical rigor,” because Torley will turn the particulars into the whole, and deflect them superficially. (You’ve seen already that he has returned to the thread he abandoned, and picked what cherries he could find. He talks sweetly, but when he’s made to look bad, there’s not much he won’t do to save face.) The burden is not on me to deconstruct the incoherence. The burden is on Torley to show that Bartlett was coherent. He obviously cannot. But he may succeed in making a bigger ass of himself yet.
Well, when they start actually looking for indications of design (not gee, it’s complex and functional), then they might begin to be worth listening to.
So far it’s, ignore all of the evidence for evolution without any pretense to explaining it, and do whatever you can to pretend that evolution can’t happen. No evidence for design, no explanation for the evidence that is the only reason why evolutionary theory exists in the first place.
All negative thus far.
Glen Davidson
Alan Fox,
Having bacteria in a citrate concentration is a designed experiment. Adaption is being artificially forced.
Tom English,
Your strength is in technically rigorous arguments like your work challenging Swamidass.
From this I have no idea why you think Bartlett is incoherent. The only reading I get from all this prose is that you emotionally can’t stand his worldview and how he chooses to promote it. The conclusion is that the only way to challange the argument is ad hominem.
You’re eminently worth listening to, but I must respond in this case that Bartlett is engaged in a priori reasoning and hasty analogy (before turning incoherent).
Or maybe it comes at least partially from the frustration of dealing with the same shit over and over again by people who are either deluded, deceptive or dumb. Or some combination of them.
For example, having tried to explain to you yourself how common descent is testable literally dusins of times, is one of the more fruitless, if not frustrating experiences I’ve had online. And I’m confident I know why. And it’s not because the only way to challenge your “argument”(read: brainless repetition of the same question) is ad hominem. And it actually pains me to say this, because unlike people like Doug Axe, Dembski and Bartlett, I don’t think you’re a bad guy Bill.
The burden is on Torley to identify the “mathematical rigor,” and to explain how it has “helped to illuminate the key issues.” If I offer up a deconstruction of Bartlett’s incoherence, Torley will try to substitute dismissal of my points for justification of his claim in the OP. He’s already shown, in his first response to me, that this is the sort of game he plays.
Do you understand the last third of Bartlett’s talk? If so, then you should be able to explain it to me. If not, then you should be asking hard questions about the impact of the talk on the students. Specifically, if the students don’t understand what Bartlett told them, but come away with the impression that YECs have brilliant challenges to Darwinism, then have they been educated, or have they been indoctrinated? I say the latter. You may disagree, but you must allow that I have good reason to be concerned.
Forced? Surely you jest?
As already pointed out, what about the strains that didn’t evolve the ability to grow in citrate aerobically? Those were “artificially forced” all the same
Forced, as in most of the populations don’t produce the adaptation.
dazz,
Yes
Tom English,
I think I understand. Let me give it a shot.
His basic thesis is that irreducibly complex systems exist defined as systems that are exceedingly unlikely to evolve with random mutation followed by selection.
His claim is that some biological systems require negative feedback loops which require chaotic systems such as class 4 computers. Any small change to a negative feedback loop will cause the feedback loop to not down regulate causing system failure. His target argument is aimed at the Darwinian mechanism random mutation and natural selection.
He sees cancer as an example of this mechanism failing through mutation.
His first test case is the Avida program where the program contains a single feedback loop which drives replication. He claims that this is an example of a chaotic class 4 system. The feedback loop is not created by running the program but is part of the original software design. He claims that Avida has not generated negative feedback loops on its own. Avida is step one in testing his hypothesis.
Rumraket,
I am glad to here you say this 🙂 I have learned a lot from your postings.
Then “artificially forced” can’t explain what happened. You’re wrong, simple as that
dazz,
If the environment had not contained the target citrate and only glucose, do you think the duplicate citrate transporter would have been fixed in the population? Remember this is a lab so the environment is designed.
I am fairly familiar with negative feedback loops, especially in ecology. The mathematics is similar whether we model population density regulation (in ecology) or feedback regulation of enzyme kinetics. In either case a change of the coefficients of the feedback system will not make it run wild, but will quite often simply change the level at which the population growth (or the enzyme levels) stabilizes, and the speed with which it responds to changes.
Neither causes total disaster, and they might even sometimes improve fitnesses.
*Butts in shamelessly*
Obviously not. Do you think Lenski expected to create a strain that could digest citrate aerobically? Lenski did not design the mutations. Lenski designed the niche. The niche was/is 37°C because E coli grow best at that temperature, in aqueous agitated suspension and provided with glucose as food because they need it, pH was/is controlled (using citrate as a buffer) to that the bacteria grow in normally. Lenski provided/s an opportunity, and a “lucky” bacterium stumbled on the opportunity. That’s how selection works, both in the wild and in an artificial environment.
That’s why I am happy to refer to selection (natural, artificial and sexual) as environmental design.
ETA present tense as the LTEE is ongoing.
PS @ Colewed?
Do you think bakers designed yeast?
Patrick,
Hey! Software developer here! I’m … oh, hang on, you’re right 🙁
colewd,
Having the bacteria utilise citrate was absolutely not the intent of the experimenters. Citrate is used as a buffer specifically because E Coli cannot normally grow on it. The experiment wasn’t done to see if it would or how long it would take. It was an unexpected occurrence which they were able to investigate because they had sampled generations.
This objection is silly. There is no citrate concentration at which their experiment could have been conducted which was not ‘designed’, simply because someone picked the value. But that range obviously must include values that can occur without any design at all, if citrate exists and God doesn’t choose the molarity of every last solution of it. It is impossible to ‘design’ a parameter value that cannot occur naturally – be it temperature, pH, solutes, etc etc etc.
It’s bizarre when even a trivial example of evolution is denied – by people who claim to accept ‘microevolution’.
Important point. Shoulda mentioned that.
An environment is an environment whether it is designed or not. Citrate exists in nature outside of laboratories.
Particular mutations don’t happen just because the citrate compound is present.
No. The local conditions in the growth flasks is what determines what is selectively beneficial, should it happen to evolve. Having citrate in the flask doesn’t make it any more likely that mutations for utilization of citrate pop up in the first place.
Nobody is “forcing” bacteria that can utilize citrate, to outcompete those that can’t. The bacteria do this all by themselves. It’s not like there are scientists sitting around poking individual bacteria and telling them to eat the citrate so-that-they-can-continue-to-grow-and-divide.
“Hey, you there.. yeah you, E coli, you need to eat this.. go! Eat it! Eat it!”
The strain with potentiating mutations was the chosen population. Natural selection?
Nah, they just annihilated the rest for their sin of refusing to eat the sacred flesh of God, transubstantiated in the form of citrate.
Inference to the best explanation FTW!
How did programmers become engineers? It immediately brings to mind calling garbage collectors sanitation engineers.
I say that having done it for 20 years.
And yes, programmers do not need to know much math, even though a lot of numerate people program.
Not only is no one forcing the bacteria to change, most of them don’t change.
This failure of the majority to change is a problem for ID.
Actually, there’s lots of change; just not lots of adaptive change. The experiment was designed to track neutral change. And neutral change is a problem for ID. It confirms Wagner’s Arrival thesis, that there are always workable alternatives to any functional sequence just a step away.
I agree. I have a degree in an actual engineering discipline and it involved learning how to cost projects and, most importantly, responsibility for human safety. Software development outside of a few places like NASA and some medical hardware firms has none of that rigor.
There are states where you can’t call yourself an engineer without a PE license, but I think the battle over that term is lost.
Joe Felsenstein,
In the case of the cell division the negative feedback is controlled by a protein destruction complex which includes the APC gene along with 4 other identified proteins that are in the complex. APC is a very large protein of around 2800 AA in length. It is sensitive to mutations which prohibit it from binding to the complex. Several APC mutations are implicated in cancer The protein that the APC destruction mechanism breaks down is beta catenin which is part of the WNT beta catenin pathway and a transcription factor for cell cycle and other proteins.
I agree with you, as you indicated by your example that this negative feedback loop can survive certain single event changes.
The open question is if random mutation and natural selection is a reasonable hypothesis for how this mechanism originated?
That is one among many open questions. Also how we account for the high number of species in the tropics.
But it is not the question I was addressing, which is the whether the negative feedback is a barrier to evolution.
Rumraket,
I agree. Thanks for the correction.
Joe Felsenstein,
JB’s argument is not against evolution per se. It is directly targeted at RMNS.
“evolution pre se” – RMNS
What remains? I’m interested to know what you consider evolution to be once we remove variation and selection.
Santa Claus.
Or the version that still fools some adults, the Designer.
Glen Davidson
OMagain,
Common Descent without an identified mechanism. This is Theobald’s argument. Variation is not removed. Random variation is.
Hi Joe Felsenstein, colewd and Tom English,
I would entirely agree that a change in the coefficients of a negative feedback system is usually not catastrophic, and may even improve fitness. In all fairness to JohnnyB, however, I don’t think that’s what he was claiming. Rather, he was claiming that such loops were difficult to evolve in the first place. Also, the changes he was envisioning weren’t just changes in the coefficients, but changes in the equations governing how they work – especially the conditions governing the loop itself and the conditions for exiting it. In his own words:
I think this is a more substantive criticism. On a programming level, one can see the point he’s getting at. The question I would ask is: what biological changes correspond to changing a variable name, or changing an operator? Also, is there any reason to suppose that the evolution of open-ended loops (in particular, negative feedback loops) is particularly fragile, in the sense that JohnnyB describes?
You don’t know what Theobald’s argument is, unfortunately.
Is the environment controlled as well?
vjtorley,
In the example I used around negative feedback in the cell cycle, I think the change would be the failure of one of the functional proteins in the destruction path or a failure in one of the proteins or small molecules that activates transcription of the protein that activates the destruction mechanism.
So as Joe points out an SNP that does not render one of the proteins non functional can be tolerated.
The pathway I am describing is in drosophila as well as humans. Without this regulation the cell will never stabilize and the organism will die.
So I think your point is valid that a step by step development involving random variation of this pathway is very unlikely.
vjtorley,
No, you are not going to home in on a particular point, far along in the talk, and pretend that because colewd brought it up, and Joe Felsenstein responded, the talk must have made sense.
Although it is probably beyond your ken, I will repeat that I am not playing rhetorical games. I’ve responded to ID math as math many times. When Bartlett gets past the preliminaries (the first two-thirds or so of his talk), he continues to use mathematical-sounding language, but what he’s saying is simply incoherent. He skates from A to B to C to D, evidently because he has made some sort of loose connection of them in his mind. (Incoherent. The points do not cohere.) Now you want to talk about D in isolation. But the fact of the matter is that Bartlett lost you at A.
If you’d joined in a discussion of the talk, rather than set yourself up (again) as a grand explicator of stuff you don’t understand, I’d have told you early on that Wolfram’s classification is of cellular automata, not Turing machines. Bartlett actually bothered to mention that, ever so briefly, in the talk (but not in his paper). He did not mention that the classification is informal. It’s Wolfram’s characterization of the different sorts of phenomena he observed in computational experiments with cellular automata.
Bartlett’s segue from computability by Turing machines to a classification of qualitative behaviors in cellular automata was not merely unjustified, but out and out bizarre. There is, in the theory of computation, a classification of formal languages called the Chomsky hierarchy (with types 0, 1, 2, and 3 of languages, each type subsuming the higher-numbered types). It seems that Bartlett has melded a vague notion of the Chomsky hierarchy of languages with the Wolfram classification of cellular automata into four types. It would be an overstatement to say that he is engaged in free association. But what he’s doing is not far from it. He makes connections between things that have somewhat the same ring, but that actually aren’t clearly related. I gather, from what he has said over the years, that he regards these connections as discoveries that he has made.
Bartlett goes on to speak of changing bits on the tape, and to describe the effects on a cellular automaton. So he’s not just made a hasty analogy. He has in fact created in his mind an amalgam of Turing machines and cellular automata. It seems that he has jumped from the Turing-equivalence of cellular automata to a hazy notion of “they basically work the same way.”
Overlooking a bunch of weird stuff, and jumping to point D, I’ll observe that there is no reason to relate the feedback “loops” in dynamical systems (the loops are in the graphical representation of the systems) to the “loops” in computer programs (the loops are, or were, in the flowchart representation of algorithms). Bartlett seems to have connected the two because of the word loop. He’s turned the concept of negative feedback into the notion of iteration of a sequence of instructions. Again, it’s not far from free association.
You can play your rhetorical games in an attempt to save face with the “onlookers.” But the active participants know that you’re doing shabby stuff. I’d advise you to build a relationship with the TSZ community, and let the onlookers take care of themselves.
P.S.–When I say, “It seems that Bartlett has…,” I am telling you the best answers I have found to the question, “What in the world might he have been thinking?” The fundamental reason that I’m asking myself the question is that his work is devoid of mathematical rigor.
Hi Tom English,
I won’t beat around the bush. You were right and I was wrong. You identified a serious flaw in Jonathan Bartlett’s slide presentation, when you wrote: “Wolfram’s classification is of cellular automata, not Turing machines.”
JohnnyB does indeed state in his slide presentation at 15:36 that Wolfram classified Turing machines into four classes, which is factually incorrect – a point which I confirmed by consulting this article on cellular automata in the Stanford Encyclopedia of Philosophy. Truth be told, I first came across Wolfram’s book about 15 years ago, so I should have been familiar with this point, but my memory has grown rusty over the years. I should have checked that Bartlett had summarized Wolfram’s work correctly, but I didn’t.
Regarding your other points: I’d prefer not to speculate as to whether Bartlett was drawing upon Chomsky’s work, but you are certainly correct when you write: “He has in fact created in his mind an amalgam of Turing machines and cellular automata.” Although cellular automata with suitable rules can emulate a universal Turing machine, the fact remains that cellular automata do not function in the same way as Turing machines.
You also make a telling point when you write:
This is a valid criticism of Bartlett’s argument.
So my question is: why did you wait several days before delivering these zingers, when you could have shot down Bartlett’s argument on day one? Your stated reason – that I didn’t join in a discussion of the talk on Bartlett’s thread, but rather set myself up on my own thread – simply won’t wash. You were the second person to comment on Bartlett’s own thread, and you could easily have pointed out the flaws in his argument to him at that stage – and enlightened many other readers in the process. But you didn’t. Frankly, I find your motives mystifying.
I might add that I wrote this post not out of a desire to “set myself up” as some sort of authority, but because (a) there were too many problems that I had identified in Bartlett’s talk for me to discuss them in a comment on his thread (I listed seven in my conclusion, many of which still stand), and also because (b) I noticed that some readers were requesting a transcript of JohnnyB’s talk. As I noted in a comment above: “My post doesn’t provide a transcript, but it does capture the nub of the argument, by quoting from the most important slides in the talk.”
I shall stop here. If you wish to respond, that’s up to you.
colewd,
One would have to remove ALL ‘random’ variation (however defined, but presumably in opposition to someone intending it). But this would be nonsensical, unless one supposes that every variant ever to occur were the result of choice (including recombinations, which would require considerable manouevring of the lives of mating partners to get them to meet, a lot of fiddling at meiosis and careful sperm/egg guidance). Which would itself be nonsensical.
Some variation must be random, surely? In which case, evolution can proceed by it.
Apparently not. I provided a link to the first Genetic Programming paper I found that discussed the evolution of such looping constructs. There are others. His claim is refuted empirically.
I saw problems with Bartlett’s argument, but chose to only express mild doubt about the analogy he was using. But, really, it was what I would call a “hand waving” argument where the details could not be filled in. And the claim about needing a universal Turing machine was absurd. The distinction between a finite automaton and a universal TM does not show up in a finite world.
Have you considered the possibility that it was your post which persuaded Tom that more needed to be said?
Your link was to the second page of comments. Tom’s reply was the second on that page. I was the second to comment on the thread.
Hi Neil Rickert,
You are right about the link. You were indeed the second to comment, early on April 21. Tom English commented later that day – or more than four days before his most recent comment of April 26. That’s a long time to hold one’s fire.
But who knows? Maybe you’re right, and the whole episode merely illustrates the Law of Unintended Consequences – although I’ve never seen it applied to thread discussions before.
Allan Miller,
Some variation is random for sure and adaption may be a result which is seen in the lab. A question is, can any transition be the result of random changes? Can all transitions be a result of random changes?