
Specifically, it looks like the genetic code is a LISP dialect.
Operon structure of genetic code:
– https://s3-us-west-2.amazonaws.com/courses-images/wp-content/uploads/sites/1094/2016/11/03164740/OSC_Microbio_11_07_Operon.jpg
{kind=link}
LISP function structure:
– http://support.ircam.fr/docs/om/om6-manual/res/listprefix.png
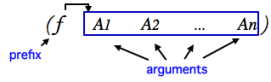{kind=link}
Nested genes:
– https://player.slideplayer.com/31/9782148/data/images/img11.jpg
{kind=link}
Nested LISP cons cells:
– https://www.tutorialspoint.com/lisp/images/treestructure.jpg
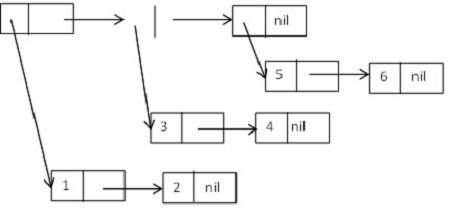{kind=link}
Who programmed/is programming it?
Other ‘programming languages’ we can study the when, where, how & most oftentimes ‘who’ did the programming & we even almost always have documentation/records of the programming process.
Otherwise, yours is just a semantic game playing with what ‘is’ is. Wow, nice & tricky!
Actually the whole cell could be said to be a QUINE program — which is lisp like.
https://en.wikipedia.org/wiki/Quine_(computing)
EXCEPT, it is also HARDWARE, not just software.
Another description of this in hardware terms is
https://en.wikipedia.org/wiki/Self-replicating_machine
But the machines of life, can self-replicate from RAW materials, not like the toy models here where the chips and parts were already pre-fabricated (aka, they were cheating):
Gregory,
Your assertion is this has no value?
A friend of mine applied the IDT principles today at work with great success. When her boss asked her to debug a piece of code to figure out what it’s doing, she replied “it was designed!”. Her boss didn’t know what to make of that so she emphatically insisted: “a mind must’ve done this!”.
She was sacked on the spot after the incident, her boss is clearly a materialist bully.
If you guys want her to make an appearance in “Expelled 2, Still no intelligent allowed!!11!11one” just let me know
If genetic code is LISP, where the hell are all the parentheses?
Actual LISP code:
[start of code]
(defparameter *small* 1)
(defparameter *big* 100)
(defun guess-my-number ()
(ash (+ *small* *big*) -1))
(defun smaller ()
(setf *big* (1- (guess-my-number)))
(guess-my-number))
(defun bigger ()
(setf *small* (1+ (guess-my-number)))
(guess-my-number))
(defun start-over ()
(defparameter *small* 1)
(defparameter *big* 100)
(guess-my-number))
[end of code]
Seriously, the pictures in the OP are only images of DNA according to one abstraction and an image of the LISP list data structure. They are not programming languages as they stand.
Now it turns out that one can use biochemistry of DNA to create a Turning Machine and even a non-deterministic UTM.
https://www.quora.com/Is-DNA-a-Turing-machine
https://royalsocietypublishing.org/doi/full/10.1098/rsif.2016.0990
One can do the similar things with eg the Game of Life. Both examples just show that people are very clever at using nature for their own purposes.
Without more explanation, neither would seem to have anything to do with the science of biology or biological evolution in particular.
ETA: clarity
… and it evolved.
Programming languages have grammar and syntax. As has been noted by numerous ID advocates, copy errors in programs are usually fatal.
Humans have, on average, a hundred copy errors, Every human. Every generation. And yet, here we are.
EricMH:
This, from the same guy who asked us not to waste his time with pointless arguments.
“It looks like” is a subjective opinion. I saw a cloud the other day that looked like a dragon. That doesn’t mean clouds are flying vertebrates.
When the ID crowd has something objective and testable, let us know.
EricMH, Sorry to be tiresome about this, but once again I call your attention to the OP you posted here on “Correspondences between ID theory and mainstream theories”. In the comments you indicated that Dembski’s use of CSI to diagnose Design had not been refuted. In the comments, I specifically argued that his argument that CSI was conserved had failed (here and here). You argued (here) that I had mischaracterized Dembski’s argument and asked (here) for a reference to show that Dembski did what I said he did.
I provided the reference, and included the money quote from it (here).
As you asked for the reference, you declared that you were disappointed in the thread and would not have further time for it. And that was it, you did not come back, even to respond to my providing the very reference you asked for.
I would be interested in showing you, there, that Dembskl’s conservation-of-CSI argument is indeed wrong.
Or should I conclude that you prefer not to discuss the validity of Dembski’s 2002 conservation-of-CSI argument?
I don’t know if that’s Gregory’s “assertion,” but I do know that this OP has no value whatsoever. Merely comparing representations and making inferences based on how similar those abstractions are. It’s some kind of a mixture of reification and being too philosophically illiterate. Even computationally illiterate, which would be surprising were it not because the writer is not any computer guy, but Eric.
If it was a programming language I would be able to learn it. It’s not. I can’t.
created for discovery my arse!
Yes, good question. This would be one testable implication of the idea. If the genome is indeed LISP like, then we could count opening and closing markers (which I understand exist) and they will be equal. On the other hand, if they do not balance, then either the nesting is just a list (e.g. <a <b <c <d ] where < is an opening marker and ] is the end of the list), or the genome is not a LISP like language.
That’d be great! Show me a formal proof Dembski’s CoCSI is wrong, and I’d be grateful. It cannot be done, however, as improbability of ASC is already proven, and is actually a well known derivation of the Markov inequality, which Dr. English credits you with pointing out.
There is such a thing as error correcting codes. IT systems are full of them, and that is what you are seeing in the genome: a programming language built upon error correcting codes. Also, you cannot get error correcting codes without intelligent design.
That’s what I was working on in your thread when you stopped going there. I gave a quote from Dembski’s 2002 book No Free Lunch showing that the specifications he used there were none of them ASC — they were all sets of genotypes that had high fitness (or equivalent). Proofs about ASC are not relevant as justifications for the CSI that he was using then, and which he has not disavowed.
It is too bad that you did not get a chance to comment on that. Can you now? The Dembski quote is in the last of the comments that I made there, which I made in response to your call for some reference. Your thoughts?
Hahahahaha, fucking priceless! You missed the “seriously” part right after Bruce’s tongue in cheek “objection” about those parenthesis, didn’t you?
Oh boy, what a laugh
It’s semantic trickery & hand-waving from the beginning, unbecoming of an Abrahamic monotheist; displaying little integrity or dignity.
Eric is, of course, under no obligation to answer serious challenges to the IDism he consumed at the DI. Highly selective answering & sometimes stonewalling are traits of not a few IDists.
As you may know, colewd, if they did answer the questions that leading scholars & scientists who are Abrahamic monotheists across a range of fields have patiently, calmly, fairly and with goodwill raised to them, the IDM would have collapsed by now. Do you disagree? As a result of this, they simply cannot act with integrity & answer those questions because too many DI salaries now depend on IDism’s perpetuation.
There certainly are such things, but the genetic code is not one of them. The genetic code is sometimes described as “error correcting”, but it’s more accurately described as structure-preserving. “Structure-preserving” means that errors (mutations) tend to have little or no effect on the resulting protein because similar DNA triplets tend to encode the same or similar amino acids. But this is not error correction; it minimizes the effect of errors, which is quite a bit different from actually correcting them.
Actual error correction codes like Hamming codes are almost the opposite of this. Rather than having errors produce valid sequences with minimally different meaning, they are set up so that errors produce invalid sequences, so that the error can be detected. In fact, the valid codes are spaced far enough apart (in sequence space) that, when an invalid code is received, there’ll only be one nearby valid code, so it’s safe to infer that the nearby valid code was the original and correct it back to that.
It’s a bit of a moot question, but do you have any basis for this claim, other than the usual “I haven’t bothered to think of a way it could happen”?
I’d turn it around on you, though: if life is intelligently designed, why don’t organisms use real error-correcting codes?
A while back I was thinking about how I’d do it if I was designing a DNA code, and worked out a five-base-per-codon code that allowed correction of any single mutation within a codon, and also made frameshift mutations give all invalid codons (after the point of the mutation). Insertions and deletions in general are hard to correct, but a run of invalid codons could easily trigger apoptosis (programmed cell death), thus removing the cell with undercoverable errors from the organism/gene pool.
(Note: this only addresses coding sequences in DNA; there’s also a good bit of functional non-coding DNA — though still a small part of the genome — and it would presumably require different error-correction systems. Also, I’m sure there are far better ways to do it than what I came up with on a whim.)
So why don’t any actual organisms have anything at all like this? I can certainly understand that some organisms might not need anything like this, but none of them? Instead, all organisms use nearly the same one-size-fits-all uncorrectable code (with minor and pretty pointless variations). Why wouldn’t a designer be more flexible and creative than that?
First peeve:
The Genetic Code is the mapping of codons to amino acids, not a set of instructions like computer code. You mean instructions, so use a different word please. Allan wrote an excellent piece right here at TSZ about it BTW.
Second peeve:
Whoops, you forget to look at the biology. What exactly is the functional equivalence between LISP cons cells and a gene residing in the intron of another gene?* Would I be wrong to believe there is none?
Third peeve:
What the hell is it with IDers and analogies?
ETA: *Correction: the intronic region. The gene in your figure is not in the intron of the host gene, since it is transcribed from the other strand.
Hi Eric:
I was trying to be funny with the parentheses bit (hence the phrase “the hell”) but I admit that my attempts at humour at TSZ probably entertain (at most) only me.
I thought that the reference to LISP was not really the issue, but that you actually had in mind the view that DNA+biochemistry can be viewed as performing a Turing machine computation, and that programming such a machine would require intelligence and design, based on all of our experience with programming.
If you want to make it about LISP in particular, I guess you would have to show that biochemistry implements a LISP interpreter with DNA as a representation of a LISP program (not just a list data structure). Seems like a lot of knowledge of both biochemistry and LISP interpreters plus some a weird (to me) morphism would be needed for that. But wouldn’t the case against naturalistic evolution via need for intelligence be the same as in the Turing case in the end?
That particular argument has already played out at TSZ under various guises, eg biosemiotics. I am not interested in revisiting it myself.
But there is a related point involving your use of Levin’s KMI results. At one point at TSZ, you mentioned that some form of learning theory might allow for an increase in KMI through naturalistic evolution, but then dismissed that as impossible. I can try to find the original post if it does not ring a bell for you.
It seems to me that the learning idea theory is worth pursuing in the context of a population of genomes learning about the environment through evolutionary processes. I don’t know how useful it is as a biological model in population genetics, but it does seem to be a way of thinking of a biological context for your use of Levin.
Joe Felsenstein,
Joe:
Further to last two paragraphs in reply to Eric, I was wondering whether computational learning theory ideas have any traction in biological population genetics. I am thinking of Leslie Valiant’s ideas on Probably Approximately Correct as applied to his concept of “ecorithm” (a play on algorithm).
https://www.quantamagazine.org/the-hidden-algorithms-underlying-life-20160128/
Are these ideas of any value to biologists working in population genetics?
I am following and enjoying your exchange with Eric, although I agree it has been rather one-sided to date.
I suppose it depends on the meaning of is.
Alright, I addressed your point again. You still are not being clear, but I do my best to guess what you are saying. However, after this response, I am finished unless you can quote the specific mistake you think Dembski makes, and provide a mathematical counter example that he is in error.
Please find my response here:
Example please, of a program that corrects itself. A link would help.
And, if you find it, please post it at UD, because , for years, the fragility of computer codes was put forth as proof that mutations can only break things.
Your reasoning seems a bit like saying that because a chair has four legs, it is a quadruped.
That’s a ridiculous objection.
Because we don’t have access to a supernatural power that exists in a world we don’t have access and blueprints to, its just semantics?
We also don’t know what makes light, so is talk of it just semantics? Nonsense.
Gregory,
If fact, I would say 99.95 of all the programming every person encounters in their life, they have no idea about the programmer, and they have never seen the documentation about the program. Does that mean we should be suspect that it is an actual program until we see that documentation?
Its an actual map? Or is this an analogy?
Really? Can you point where Allan, or someone else, proves, or explains how exactly the genetic code is mapping spatiotemporal information in embryo development during cell differentiation process?
I think DNA is a cosmic letter soup that the Flying Spaghetti Monster prepared one day. I have no evidence to show for, I can’t show and I don’t care how, why, where or when that happened and I have no idea where the ingredients came from, but that’s true of most soups, isn’t it?
It’s an analogy to use the word mapping to describe the physical causal relationship that exists between amino acid and nucleotide sequence.
For once I actually agree with you. Knowing the programmer (and when he/she/it created the program) is irrelevant, because whether the entity in question technically qualifies as a program or not does not tell us how it came to exist.
If the genetic code qualifies as a programming language, then the genetic code is a counterexample to the claim that programming languages are all created by intelligent designers, because the genetic code was not created by an intelligent designer, it evolved. So the people who advance the claim that the genetic code is a programming language do not thereby establish (supposing they succeed in showing it qualifies as a programming language) that it was intelligently designed.
The genetic code is optimal for error-free information processing and doesn’t really need an error correction system.
Replication of DNA and synthesis of proteins are studied from the view-point of quantum database search. Identification of a base-pairing with a quantum query gives a natural (and first ever!) explanation of why living organisms have 4 nucleotide bases and 20 amino acids. It is amazing that these numbers arise as solutions to an optimisation problem. Components of the DNA structure which implement Grover’s algorithm are identified, and a physical scenario is presented for the execution of the quantum algorithm. It is proposed that enzymes play a crucial role in maintaining quantum coherence of the process. Experimental tests that can verify this scenario are pointed out.
In other words, the 4 nucleotide bases and 20 amino acids were predicted by equations of quantum mechanics to be optimal for error-free information translation. Here is another kicker: they are optimal to maintain quantum coherence in DNA. This means that mutations are regulated by quantum processes and it is possible that double helix is held intact by quantum entanglement…
Any old shit is possible if reality does not constrain you.
How many mutations do you personally have?
Sure. Your eyes are cameras, your nerves are telephone wires and your brain is a computer. Isn’t it obvious?
HELLO WORLD
Woops, sorry. Don’t know where that came from.
Not to mention phoodoo’s brain constant segmentation faults.
No, I can’t, because that would be silly.
I could post an OP titled “The Sun is a Grapefruit”
The sun is round.
A grapefruit is round.
The sun is yellow.
A grapefruit is yellow.
The sun comes up in the morning.
I usually see grapefruit only in the morning.
The sun must be a grapefruit.
Who’s with me ?
And please don’t tell me that the sun is flat. I will only respond that the sun must be a slice of a grapefruit.
ETA: I forgot one…. if you get it straight in your eye, it kinda burns. That REALLY clinches it.
The program _is_ the documentation. A scrambled mess is the product of a poor programmer. Typically you learn the way the program works by examining the tests, as they exercise the functionality of the application in a controlled manner.
So, if the genetic code is a program then where are the tests? How do we run them?
Don’t tell me you worship a deity that cannot be bothered to write tests? Very very unprofessional.
Of course! Just like in many science fiction stories everything has to make sense without the need for explaining how and when…In the cell differential process the cells “know” precisely what to become, where to go and when… There is no need of explaining the details where spatiotemporal information, or instructions, come from…
It is another evolutionary magic… 🙂
Praise the Darw!
Sure there is. But the genetic code is a mapping of codons to amino acids, not to developmental instructions. You are just being confused again.
I am pretty sure you are not being serious on this, but I suppose one could continue the analogy by saying God wrote the tests into the environment (possibly by fine tuning the created universe). A particular genome fails the test by leading to an organism that is less fit than those developing from other genomes..
But I rather doubt that biologists find any scientific value in a computational model of DNA as input tape and biochemistry as Turing Machine.
But I don’t know. Computational models are very valuable to the cognitive sciences, so they cannot be rejected out of hand as unscientific. I don’t see any issue in explaining computational mechanisms via evolutionary mechanisms, learning mechanisms, and possibly cultural change (but definitely not “cultural evolution”. That is out of the question, of course)
Eric,
Since you are a mathematician you should look into the category theory that stems from the set theory in relation to embryo development…
The instructions for embryo development are beyond DNA, or the mapping of codons to amino acids…
The evidence for quantum (shadow) information in DNA is beyond Darwinism or any other theory materialistic theory to explain…
http://theskepticalzone.com/wp/does-embryo-development-process-require
I’m sure there is…
And?
I will make it easier for you…
Where does spatial information come from in protein folds?
You do know what I’m talking about, right?
How quantum entanglement in DNA synchronizes double-strand breakage by type II restriction endonucleases
https://www.ncbi.nlm.nih.gov/pmc/articles/PMC4746125/
The OP you link to finishes:
So on one hand you admit there’s no actual evidence for it (if this is all true i.e. it’s not yet shown to be true) and then on the other hand it’s become “evidence” for what you are claiming now?
There’s a reason ID “science” never produces anything useful. It’s built on a house of cards just like the pitiful one you are trying to construct here.
I was going to see if anyone mentioned that. It’s basically theistic evolution, and that’s game over for ID 🙂