
Background
For the past month or so I’ve been investigating the claim that the phylogenetic signal is evidence that a dataset shares common descent.
Supposedly, the phylogenetic signal is one of, if not the, strongest pieces of evidence for common descent. It is one of the first of the 29+ evidences for evolution offered over at Talk Origins (TO).
Quoting from the article:
The degree to which a given phylogeny displays a unique, well-supported, objective nested hierarchy can be rigorously quantified. Several different statistical tests have been developed for determining whether a phylogeny has a subjective or objective nested hierarchy, or whether a given nested hierarchy could have been generated by a chance process instead of a genealogical process (Swofford 1996, p. 504). These tests measure the degree of “cladistic hierarchical structure” (also known as the “phylogenetic signal”) in a phylogeny, and phylogenies based upon true genealogical processes give high values of hierarchical structure, whereas subjective phylogenies that have only apparent hierarchical structure (like a phylogeny of cars, for example) give low values (Archie 1989; Faith and Cranston 1991; Farris 1989; Felsenstein 1985; Hillis 1991; Hillis and Huelsenbeck 1992; Huelsenbeck et al. 2001; Klassen et al. 1991).
http://www.talkorigins.org/faqs/comdesc/section1.html#nested_hierarchy
I’ve been skeptical of this claim. A tree is just one kind of directed acyclic graph (DAG), and my hunch is many kinds of DAGs will also score highly on metrics for phylogenetic signal. I picked one metric, the consistency index (CI), which according to Klassen 1991 is the most widely used metric. It also is the featured metric in the above TO article. Plus, it is very simple to calculate. So, I’ve focused my efforts on the CI metric.
Result
What I have found is that my hunch is correct. It is simple to create a DAG that scores highly in CI, well within the range of published CI scores for real datasets.
Consequently, it is incorrect to say the phylogenetic signal is strong evidence for evolution. In particular, this claim is provably false (as I have proven here):
Phylogenies based upon true genealogical processes give high values of hierarchical structure, whereas subjective phylogenies that have only apparent hierarchical structure give low values.
http://www.talkorigins.org/faqs/comdesc/section1.html#nested_hierarchy
How have I proven it false? I generate DNA sequences from directed acyclic graphs, and the trees derived from these sequences using well established methods produce CI scores well within published ranges. Here are two such experiments plotted on the chart from Klassen 1991:
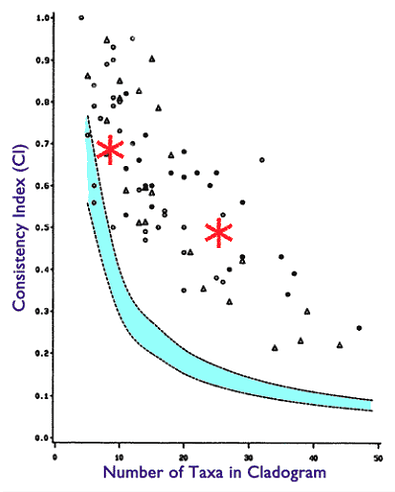
This is a phylogeny with very high value of hierarchical structure not generated from a true genealogical process.
Methods
To reproduce my results you can run the DAG dataset generator here: https://repl.it/@EricHolloway/Phylogenetic-Signal-Fallacy-Nucleotide-Level
Take the generated DNA sequences, which are in FASTA format, and paste them into the ClustalW online tool.
Take the results of the ClustalW tool, and use the PAUP software to generate trees and measure CI scores. You’ll need to fiddle with the NEX file format, so to save you the trouble, I’ve included an already created NEX file that I’ve generated from the aforementioned process, which you can pop into PAUP.
Once you load a NEX file into PAUP, here are the steps to generate trees, and then measure CI.
- Press “Generate Trees” in the “Trees” menu.
- Press the “OK” button.
- Press “Describe Trees” in the “Trees” menu.
- Press the “Describe” button.
- You will see something like the following:
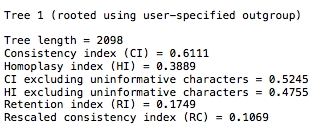
You will find the 27 taxa in the file will generate CI scores in the range of 0.48-0.53. If you look at the Klassen 1991 chart, you will see this is well within published scores for that number of taxa.
Conclusion
So, what is my takeaway from this?
Basically, highly statistically significant CI scores do not indicate common descent. They can just as easily be generated by a DAG. Therefore, we cannot infer common descent from high CI.
Furthermore, insofar as CI is representative of the state of phylogenetic signal measurement, my result undermines the more general claim that phylogenetic signal indicates common descent.
As such, the Talk Origin’s claim that the nested hierarchy of species is well attested by the data is highly questionable if not outright false, and should be retracted as evidence for evolution until such time as a much more rigorous analysis with DAG eliminating controls is established.
Addendum
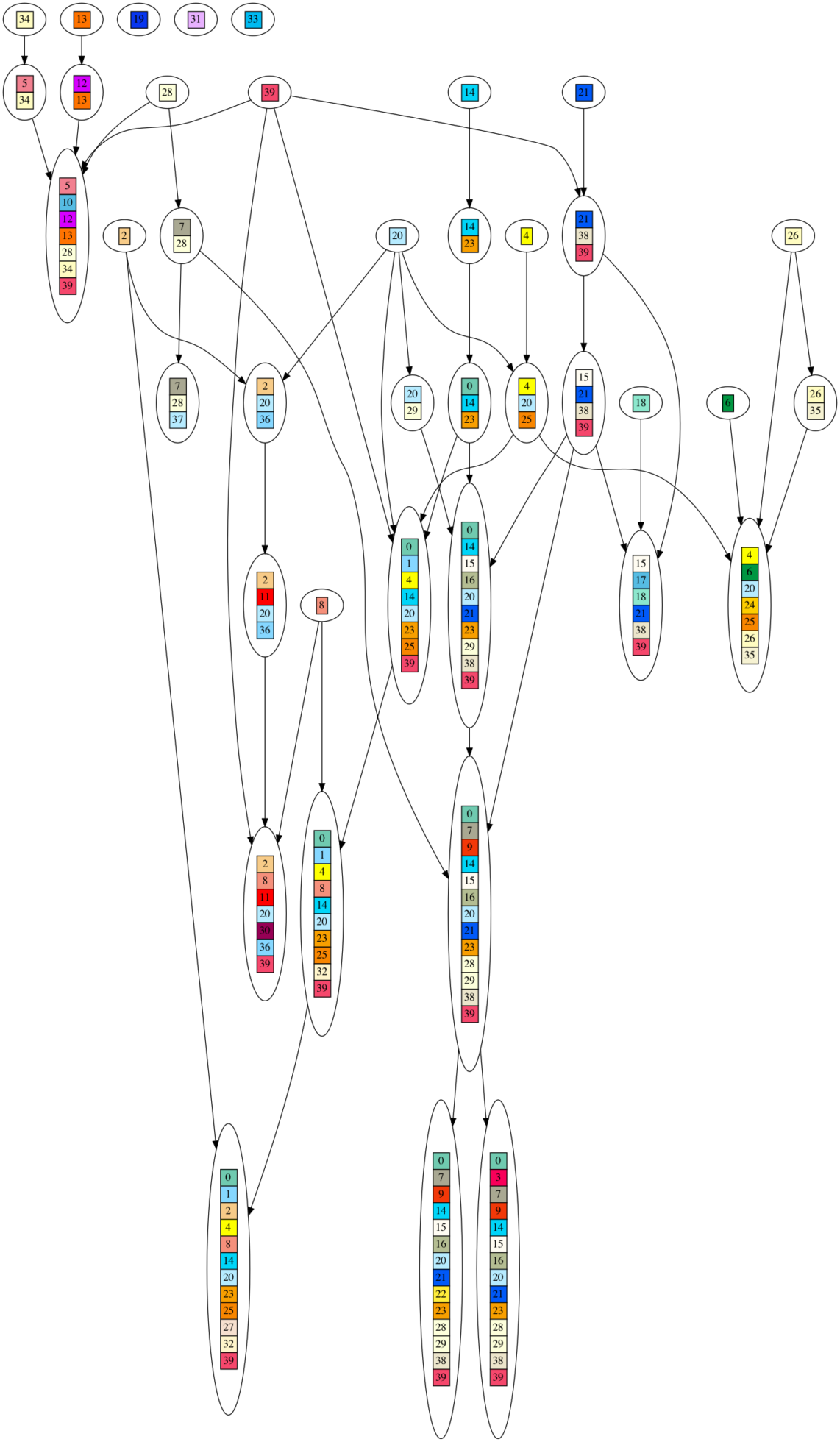
To visually illustrate what I mean by a DAG generating the DNA sequences, here is a graph of one such DAG. Each colored/numbered box represents a gene, which is replaced by a unique, randomly generated (uniform over ‘GATC’) DNA sequence of 20-30 letters long in post processing. Arrows indicate when ‘ancestor’ gene sets are combined into larger gene sets. If you look closely, you will see each gene set contains the union of all incoming gene sets, plus one new gene. As you can see, this looks nothing at all like an evolutionary process, yet it produces very high phylogenetic signal as measured by the consistency index (CI) metric.
I don’t think the first person to have written the story was the original author. I believe that it would have been handed down as an oral tradition long before it was ever consigned to the written word. This oral tradition was carried on by Jesus. As far as we know he never committed anything to writing and he was renowned for speaking in parables in which moral lessons could be conveyed regardless of whether or not the story had any literal truth.
I believe that there’s a more important lesson in the story of the ark that doesn’t rely on, nor require one to believe that it was actually built.
Brilliant! Just Brilliant! Not that you should take credit though. You could just be a victim of your educational background.
The term vacuous comes to mind. That someone might be a victim of their educational background would appear to apply to anyone and everyone.
Perhaps some people have interest in this open access book Phylogenetics in the Genomic Era.